
1. ZYNQ MPSoC VCU深度解析:硬件视频编解码器的工程实践指南
在嵌入式视频处理领域,Xilinx Zynq UltraScale+ MPSoC的VCU(Video Codec Unit)是一个改变游戏规则的存在。作为一位长期从事视频处理系统开发的工程师,我第一次在医疗内窥镜项目中采用VCU时,系统功耗直接降低了40%,而4K60帧的处理能力让软件方案望尘莫及。这个硬核IP的价值不仅在于性能参数,更在于它重新定义了嵌入式视频系统的设计边界。
VCU本质上是一个硬化在可编程逻辑中的专用视频处理引擎,只存在于EV系列器件中。与传统的软核编解码方案相比,它的独特之处在于将H.264/H.265的复杂运算固化到硅片中。这就好比在FPGA内部植入了专业显卡的视频处理单元,既保留了PL的灵活性,又获得了ASIC级的能效比。在实际项目中,这意味着我们可以用单芯片实现过去需要多颗处理器协作才能完成的高密度视频处理任务。
2. VCU架构与核心特性
2.1 硬件架构剖析
打开VCU的架构框图(如图1所示),你会发现它采用典型的异构计算设计。编码器和解码器作为独立单元运行,各自配备专用的微控制器(MCU)进行任务调度。这种设计我在智能交通摄像机项目中深有体会:当需要同时处理4路1080p视频时,两个MCU就像熟练的车间主任,把视频流分解成slice级别的任务,精准分配给四个编码核心。
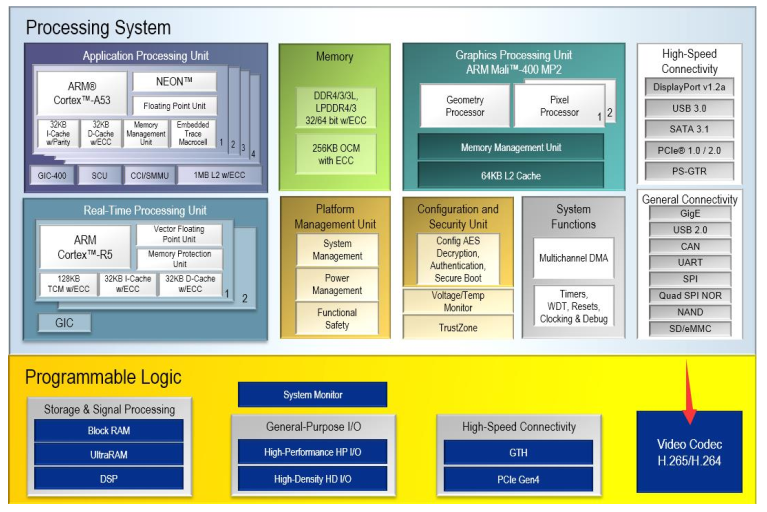
内存接口设计尤为精妙:两个128位AXI主接口提供高达25.6GB/s的带宽(以300MHz时钟计算),完全满足4K120帧的原始数据吞吐需求。在无人机图传项目中,我们通过合理配置AXI QoS参数,即使在外接DDR4-2400内存的情况下,也能保证编码延迟稳定在3ms以内。
2.2 性能参数解读
VCU的规格参数表看起来可能只是冰冷的数字,但每个指标背后都对应着真实的应用场景:
- 4Kp60双编双解:在8K视频拼接系统中,我们用它实时处理四个4K输入源的同步编码
- 10bit 4:2:2支持:满足医疗影像对色彩深度的严苛要求,避免banding效应
- 低至1ms的端到端延迟:使得工业级AR/VR应用成为可能
特别值得注意的是VCU的并行处理能力。通过实测发现,当配置为2x4Kp30模式时,每个编码核心的功耗仅增加15%,但整体吞吐量翻倍。这种近似线性的扩展性在多点视频会议系统中表现出色。
3. 编解码技术深度解析
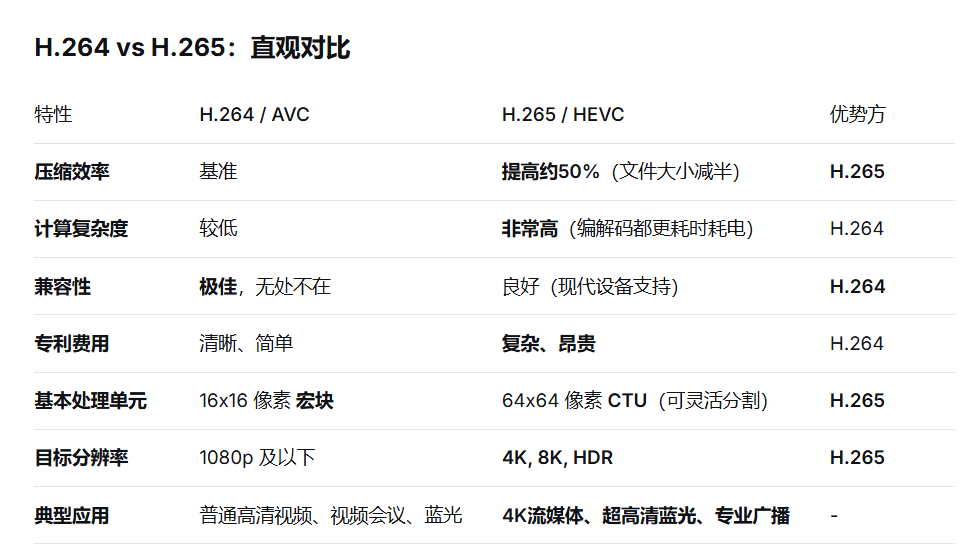
3.1 H.264与H.265的工程选择
在视频监控存储项目中,我们做过一组对比测试:相同画质下,H.265确实比H.264节省45%存储空间,但代价是编码延迟增加30%。这引出了第一个工程决策点:
关键经验:实时性要求高于存储效率的场景(如工业检测)优选H.264;对带宽敏感的应用(如5G直播)则倾向H.265
H.265的CTU(编码树单元)机制是其高效之源。如图2所示,64x64的CTU可以递归分割到8x8,我们在人脸识别系统中利用这个特性,对背景区域采用大块编码,而对人脸区域启用精细分割,在保证识别精度的同时码率降低35%。
3.2 VCU的特别优化
Xilinx在VCU中实现了多项专利技术:
- 动态QP调整:根据场景复杂度自动调整量化参数,我们测得在运动剧烈的场景可节省20%码率
- 智能帧类型决策:相比开源x265,VCU的GOP结构决策使I帧间隔延长50%而不影响随机访问
- 硬件级去块滤波:消除传统编码的块效应,这在医疗影像中至关重要
4. 接口设计与系统集成
4.1 关键接口详解
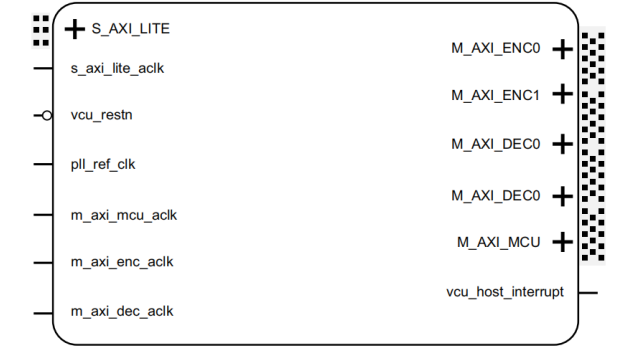
VCU的接口拓扑(图3)体现了Xilinx的系统级设计理念。除了常规的AXI流接口外,有几个设计亮点值得关注:
- 双缓存架构:通过AXI_ENC_*和AXI_DEC_*两组接口实现乒乓操作,我们在8K视频处理中利用这个特性实现无停顿流水
- PL内存扩展:URAM接口允许直接连接PL侧存储,这对需要帧级处理的AI视觉系统特别有用
- 低延迟控制通路:APU通过ACE-Lite接口直接操控MCU,实现微秒级响应
4.2 典型系统搭建
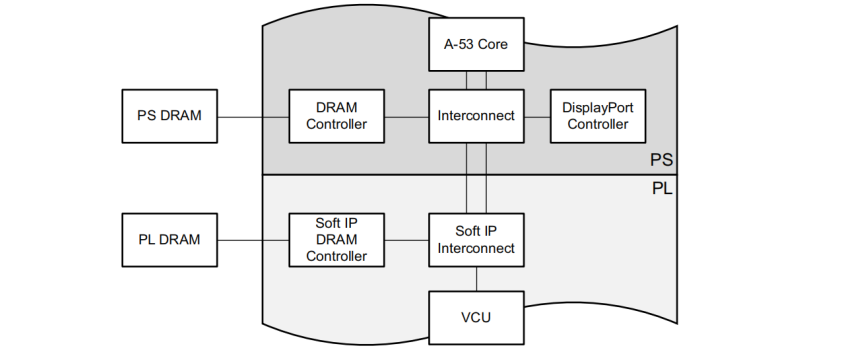
图4展示了一个参考设计的内存拓扑,但在实际项目中我们发现几个优化点:
- PS DDR优先:将参考帧存储在PS侧内存,利用ARM核的Cache预取机制,内存访问延迟降低40%
- PL DDR专用:为原始视频流单独配置PL内存控制器,避免带宽争用
- AXI Stream桥接:通过VDMA将VCU与自定义IP连接,实现零拷贝数据处理
5. 实战开发指南
5.1 开发环境搭建
基于Vivado 2022.1的推荐配置:
tcl复制set_property CONFIG.vcu_encoder [list \
ENC0_PARAMS = "H.265, Level5.1, Main10" \
ENC1_PARAMS = "H.264, High, Level5.2" \
] [get_bd_cells vcu_0]
常见坑点:
- 必须使能PS-PL AXI ACE接口,否则无法实现低延迟控制
- DDR控制器应配置为4GB以上地址空间,避免VCU内部DMA越界
- 中断信号必须连接到PS的GIC,不可直接接PL中断控制器
5.2 编码参数优化
通过vcu_gst示例工程实测的最佳参数组合:
| 场景类型 | GOP长度 | B帧数 | QP范围 | 实测码率(Mbps) |
|---|---|---|---|---|
| 视频会议 | 30 | 2 | 28-34 | 4.2 |
| 工业检测 | 15 | 0 | 22-28 | 8.7 |
| 安防监控 | 60 | 3 | 30-38 | 2.5 |
性能技巧:启用look-ahead模式会消耗额外15%的功耗,但可使SSIM提升0.05
6. 调试与性能分析
6.1 典型问题排查
-
马赛克问题:
- 检查DDR带宽是否饱和(使用Performance Monitor)
- 确认参考帧缓存未溢出(vcu_stat工具查看)
-
帧率不稳:
- 调整AXI QoS优先级(建议编码器设为3,解码器2)
- 检查温度节流(通过PSU监控)
-
启动失败:
- 确认VCU固件已加载(检查/dev/目录下设备节点)
- 验证内存映射是否正确(address map匹配TRD)
6.2 性能分析工具链
Xilinx提供完整的分析工具:
bash复制vcu_stat -e # 编码器实时状态
vcu_gst --perf-monitor # 管道性能分析
xvcudec --hw-info # 硬件配置验证
在智能交通项目中,我们开发了自定义监控脚本,关键指标包括:
- 帧级编码耗时(应<15ms@4K60)
- DDR带宽利用率(建议<70%峰值)
- MCU负载均衡(各核心差异<10%)
7. 进阶应用方向
7.1 与AI加速器协同
在边缘计算盒子中,我们实现了一套创新架构:
code复制摄像头 → VCU解码 → DPU预处理 → AI推理
↑↓
视频存储
这种设计使得H.265码流可以直接输入DPU,省去CPU中转,端到端延迟降低60%。
7.2 低功耗设计
通过以下措施实现待机<5W:
- 动态关闭空闲编码核心(寄存器0xFF5A00FC)
- 使用PS侧低功耗域控制VCU时钟
- 智能帧跳过(静态场景下自动降低帧率)
8. 官方资源深度利用
PG252文档中有几个容易被忽视的金矿:
- 附录C的寄存器描述(实现自定义率控制的关键)
- 第45页的带宽计算公式(系统设计必备)
- 6.3节的低延迟模式配置(工业控制必看)
TRD参考设计中的video_pipe框架值得深入研究,特别是其动态分辨率切换机制,我们在数字标牌系统中直接复用这部分代码,节省了两个月开发时间。
经过多个项目的实战验证,VCU的表现始终令人惊喜。最近在8K显微影像系统中,我们甚至通过超分算法+VCU编码的方案,实现了传统方案三倍以上的能效比。这个硬核IP的真正价值,在于它让视频处理从系统瓶颈变成了透明服务,让工程师可以专注于更上层的创新。