
1. ARMv7 Cache机制概述
在嵌入式系统开发中,Cache作为CPU与主存之间的高速缓冲存储器,对系统性能有着决定性影响。ARMv7架构采用了多级Cache设计,通过精巧的硬件机制和指令集支持,实现了高效的内存访问。本文将深入解析ARMv7 Cache的工作原理,特别是三种典型场景下的Cache一致性处理方案,以及对应的底层汇编实现。
提示:理解Cache机制需要同时关注硬件特性和软件操作,本文将从这两个维度展开,适合嵌入式开发工程师、系统程序员以及对计算机体系结构感兴趣的读者。
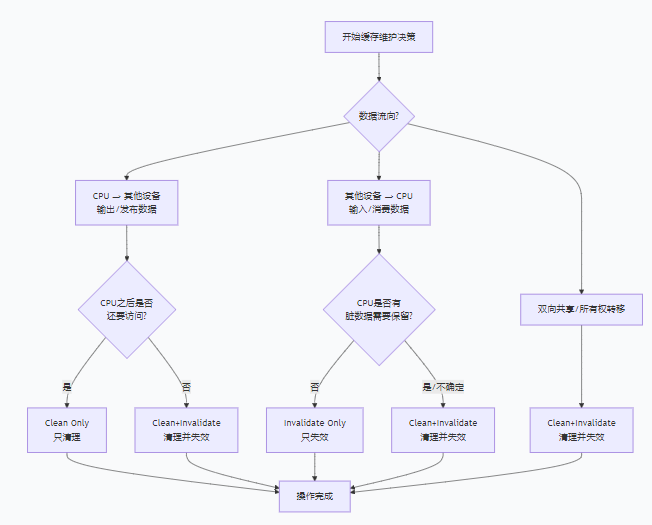
2. Cache一致性场景解析
2.1 CPU准备让其他主设备读取数据
典型场景是DMA输出操作(CPU → 外设)。当CPU修改数据后需要让外设读取时,必须确保:
- CPU的修改已经写回主存
- 外设能从主存获取最新数据
- 保留Cache副本供CPU后续使用
此时应选择Clean操作:
c复制clean_cache_range(buffer, size);
// 对应汇编指令:DCCMVAC
Clean操作仅将脏数据写回内存,不会使Cache失效。这种选择性写回机制避免了不必要的Cache重载,特别适合CPU会重复访问相同数据的场景。
实战经验:在Linux DMA-BUF共享内存机制中,导出方(exporter)在传递缓冲区前必须执行Clean操作,这正是该场景的典型应用。
2.2 其他主设备修改数据后CPU读取
典型场景是DMA输入(外设 → CPU)。当外设写入数据后CPU需要读取时,必须:
- 丢弃CPU Cache中的旧副本
- 强制从主存加载新数据
此时应选择Invalidate操作:
c复制invalidate_cache_range(buffer, size);
// 对应汇编指令:DCIMVAC
关键前提:确保该内存区域没有CPU需要保留的脏数据。若有疑问,应先执行Clean或直接使用Clean+Invalidate组合操作。
2.3 双向共享缓冲区处理
当CPU和外设交替读写同一块内存时(如环形缓冲区),需要完整的缓存行所有权转移:
c复制clean_invalidate_cache_range(buffer, size);
// 对应汇编指令:DCCIMVAC
该操作原子性地完成清理和失效,确保:
- CPU的修改已持久化到内存
- 后续读取能获取外设的最新写入
- 避免竞态条件导致的数据不一致
3. ARMv7 Cache核心架构
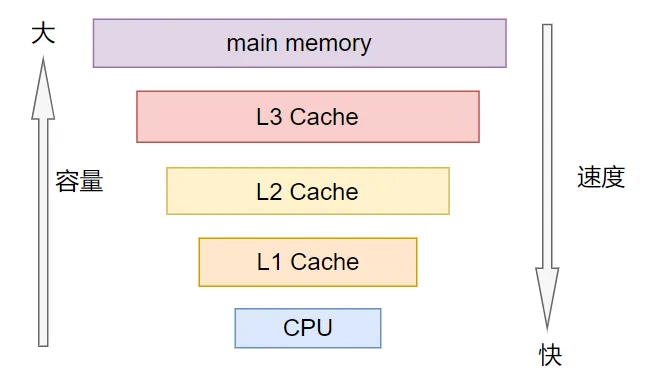
3.1 多级Cache存储结构
ARMv7采用典型的三级Cache架构:
- L1 Cache:分指令(I-Cache)和数据(D-Cache),通常32KB
- 访问延迟:2-3个时钟周期
- 4-way组相联(D-Cache)
- L2 Cache:统一缓存,大小256KB-1MB
- 访问延迟:10-20个时钟周期
- 8-way组相联
- L3 Cache:部分SoC配置,大小1-8MB
- 访问延迟:20-40个时钟周期
3.2 Cache Line关键机制
Cache Line是Cache管理的最小单位,ARMv7通常配置为32字节。其地址解码包含三个关键字段:
| 字段 | 位宽 | 作用 |
|---|---|---|
| Tag | [31:13] | 标识内存块唯一性 |
| Index | [12:5] | 定位Cache组(set) |
| Offset | [4:0] | 定位Line内的具体字节 |
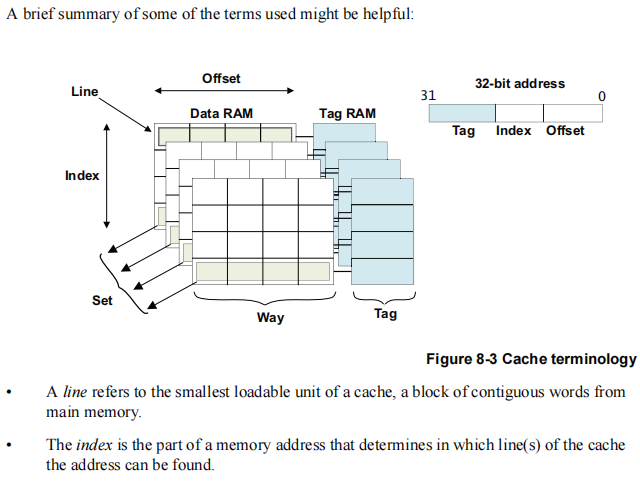
当CPU访问地址0x12345678时:
- 提取Index位[12:5]定位目标Cache组
- 比较所有Way的Tag与地址[31:13]
- 匹配成功后根据Offset读取具体数据
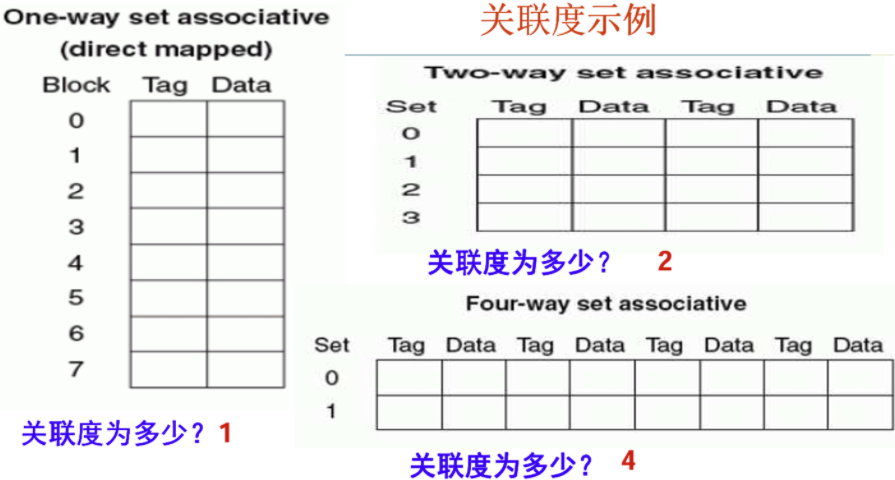
3.3 组相联实现方式
ARMv7采用固定组相联设计:
- L1 D-Cache:4-way
- L1 I-Cache:2-way
- L2 Cache:8-way
高相联度减少冲突未命中,但增加硬件复杂度。替换算法通常采用伪LRU(Least Recently Used)。
4. Cache控制寄存器详解
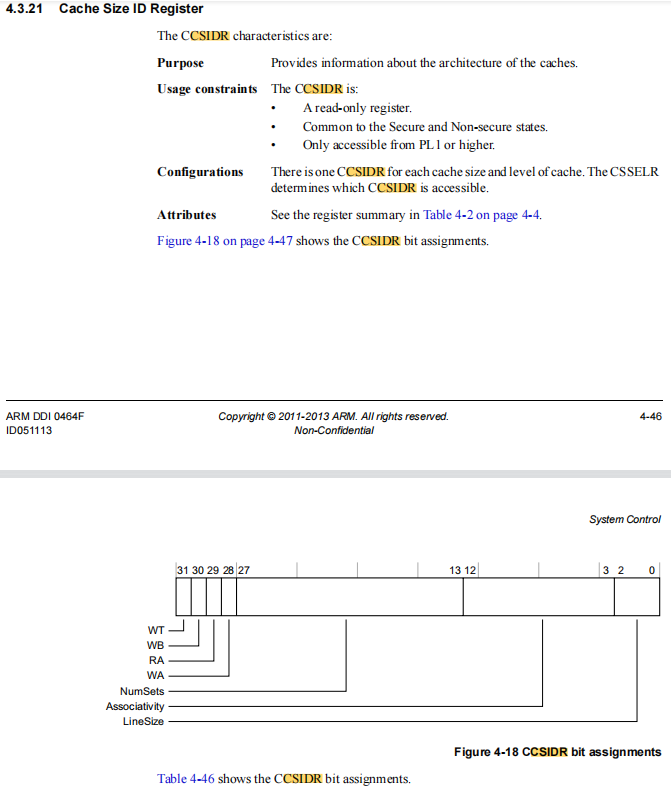
4.1 CSIDR寄存器布局
通过CP15协处理器访问的Cache Size ID Register(CSIDR)包含关键Cache参数:
| 字段 | 位域 | 描述 |
|---|---|---|
| LineSize | [2:0] | Cache line大小编码(N=2^(LineSize+2)) |
| Associativity | [12:3] | Way数量-1 |
| NumSets | [27:13] | Set数量-1 |
| WT | [28] | Write-Through标志 |
| WB | [29] | Write-Back标志 |
| RA | [30] | Read-Allocate标志 |
| WA | [31] | Write-Allocate标志 |
4.2 Cache参数读取实例
通过汇编代码读取D-Cache line大小:
assembly复制.macro dcache_line_size, reg, tmp
mrc p15, 1, \tmp, c0, c0, 0 @ 读取CSIDR
and \tmp, \tmp, #7 @ 提取LineSize字段
mov \reg, #16 @ 基础值16字节
mov \reg, \reg, lsl \tmp @ 计算实际line大小
.endm
执行流程:
- 读取CSIDR到临时寄存器
- 提取低3位得到LineSize编码
- 基础值16左移编码位数得到实际大小
- ARMv7典型结果为32字节(编码1,16<<1)
5. Cache操作汇编指令解析
5.1 关键指令功能对比
| 指令 | 功能描述 | 使用场景 |
|---|---|---|
| TST | 位测试,设置条件标志 | 检查地址对齐 |
| BIC | 位清除 | 地址对齐操作 |
| MCRNE | 条件协处理器写入 | 非对齐地址的特殊处理 |
| BLO | 无符号小于跳转 | 循环控制 |
| DSB | 数据同步屏障 | 保证内存操作完成 |
5.2 典型指令实现细节
TST指令:
assembly复制tst r0, r3 @ r0 & r3
- 执行按位与操作但不存储结果
- 根据结果设置Z(零)标志位
- 常用于检查地址对齐(r3通常为line_size-1)
BIC指令:
assembly复制bic r0, r0, r3 @ r0 = r0 & ~r3
- 将r0与r3的反码按位与
- 实现地址向下对齐到Cache line边界
DCCIMVAC操作:
assembly复制mcr p15, 0, r0, c7, c14, 1
- 对地址r0执行Clean+Invalidate
- 操作粒度为一个Cache line
- 必须配合DSB指令保证完成
6. Cache操作底层实现
6.1 dcache_inv_range实现分析
c复制void v7_cache_inv_range(start, end)
{
line_size = dcache_line_size();
align_mask = line_size - 1;
// 处理起始地址非对齐部分
if (start & align_mask) {
clean_invalidate_line(start & ~align_mask);
start = (start + line_size) & ~align_mask;
}
// 处理结束地址非对齐部分
if (end & align_mask) {
clean_invalidate_line(end & ~align_mask);
end &= ~align_mask;
}
// 循环失效所有完整Cache line
while (start < end) {
invalidate_line(start);
start += line_size;
}
dsb();
}
关键点:
- 特殊处理非对齐的首尾行(避免影响相邻数据)
- 批量失效中间完整对齐的Cache line
- DSB确保所有操作完成
6.2 dcache_clean_range优化技巧
assembly复制v7_cache_clean_range:
dcache_line_size r2, r3
sub r3, r2, #1
bic r0, r0, r3
1:
mcr p15, 0, r0, c7, c10, 1 @ DCCMVAC
add r0, r0, r2
cmp r0, r1
blo 1b
dsb
mov pc, lr
性能优化:
- 使用循环展开减少分支预测开销
- 对齐访问避免额外Clean操作
- 批量处理连续Cache line
6.3 完整Cache刷新流程
c复制void v7_cache_flush_range(start, end)
{
line_size = dcache_line_size();
align_mask = line_size - 1;
start &= ~align_mask;
while (start < end) {
clean_invalidate_line(start);
start += line_size;
}
dsb();
}
注意事项:
- 必须保证操作区间是Cache line对齐的
- 在SMP系统中需要额外处理CPU间一致性
- 操作期间应禁用中断避免竞态条件
7. 性能优化实践
7.1 数据预取策略
通过PLD指令实现智能预取:
assembly复制pld [r0, #128] @ 预取r0+128处数据
最佳实践:
- 在循环开始前预取2-3次迭代需要的数据
- 步长设置为Cache line大小的整数倍
- 避免过度预取导致Cache污染
7.2 关键参数调优
通过CTR寄存器获取Cache信息:
c复制unsigned get_cache_params(void)
{
unsigned ctr;
asm volatile("mrc p15, 0, %0, c0, c0, 1" : "=r"(ctr));
return ctr;
}
调优建议:
- 根据DminLine调整数据结构对齐
- 根据Cache大小分块处理大型数组
- 关键数据结构大小应避免等于Cache way大小
7.3 多核一致性处理
SMP系统中的额外操作:
c复制void smp_cache_flush(void *addr)
{
flush_dcache_range(addr, PAGE_SIZE);
dsb();
smp_call_function(__flush_cache, NULL, 1);
}
核心要点:
- 本地CPU先执行Clean+Invalidate
- 通过IPI通知其他CPU失效对应Cache line
- 使用DMB/DSB保证操作顺序性
8. 常见问题排查
8.1 数据一致性问题症状
| 现象 | 可能原因 | 解决方案 |
|---|---|---|
| DMA读取到旧数据 | 未Clean CPU Cache | 执行Clean操作 |
| CPU读取到DMA旧数据 | 未Invalidate Cache | 执行Invalidate操作 |
| 随机数据损坏 | 并发访问冲突 | 添加内存屏障 |
8.2 性能问题分析
Cache性能计数器事件:
- L1D_CACHE_REFILL:L1未命中次数
- L1D_CACHE_WB:写回次数
- L2D_CACHE_REFILL:L2未命中次数
优化方向:
- 减少L1未命中:优化数据局部性
- 减少L2未命中:调整数据结构大小
- 减少写回:合并写操作
8.3 调试技巧
通过FSR/FAR寄存器定位Cache错误:
c复制void show_cache_fault(void)
{
unsigned fsr, far;
asm volatile("mrc p15, 0, %0, c5, c0, 0" : "=r"(fsr));
asm volatile("mrc p15, 0, %0, c6, c0, 0" : "=r"(far));
printf("Cache fault at 0x%08x, status 0x%08x\n", far, fsr);
}
常见错误码:
- 0x1:对齐错误
- 0x5:Cache维护操作错误
- 0x8:外部abort
在嵌入式开发实践中,我经常遇到因Cache配置不当导致的隐蔽问题。一个典型案例是在DMA传输完成后,由于忘记执行Cache无效操作,CPU读取到了缓存中的旧数据。这种问题在调试时往往表现为"时好时坏"的特性,通过系统性地理解Cache一致性机制,才能快速定位这类问题。建议在开发初期就建立完善的Cache维护规范,特别是在以下三个关键点必须执行正确的Cache操作:
- DMA传输起始前
- DMA传输完成后
- 内存共享区域访问前后