
1. 多级逻辑综合概述
在VLSI CAD领域,逻辑综合是将高级硬件描述转换为优化门级网表的关键步骤。与传统的两级逻辑综合相比,多级逻辑综合通过引入中间变量层级,能够在面积优化方面获得显著优势,同时兼顾时序约束。这种折衷方案在现代芯片设计中尤为重要,因为纯粹的两级逻辑(如PLA实现)虽然速度快,但会带来难以接受的面积开销。
多级逻辑的核心思想是通过代数分解技术,将复杂布尔表达式分解为多级结构。这种分解需要解决三个关键问题:
- 如何量化多级逻辑的复杂度
- 如何寻找最优的分解方式
- 如何利用设计中的"无关项"(Don't Care)进行进一步优化
实际工程经验:在28nm工艺节点下,采用多级逻辑综合相比两级逻辑平均可减少35%的面积,但会引入约15%的时序退化。这种trade-off在移动设备芯片设计中尤为关键。
2. 多级逻辑复杂度评估
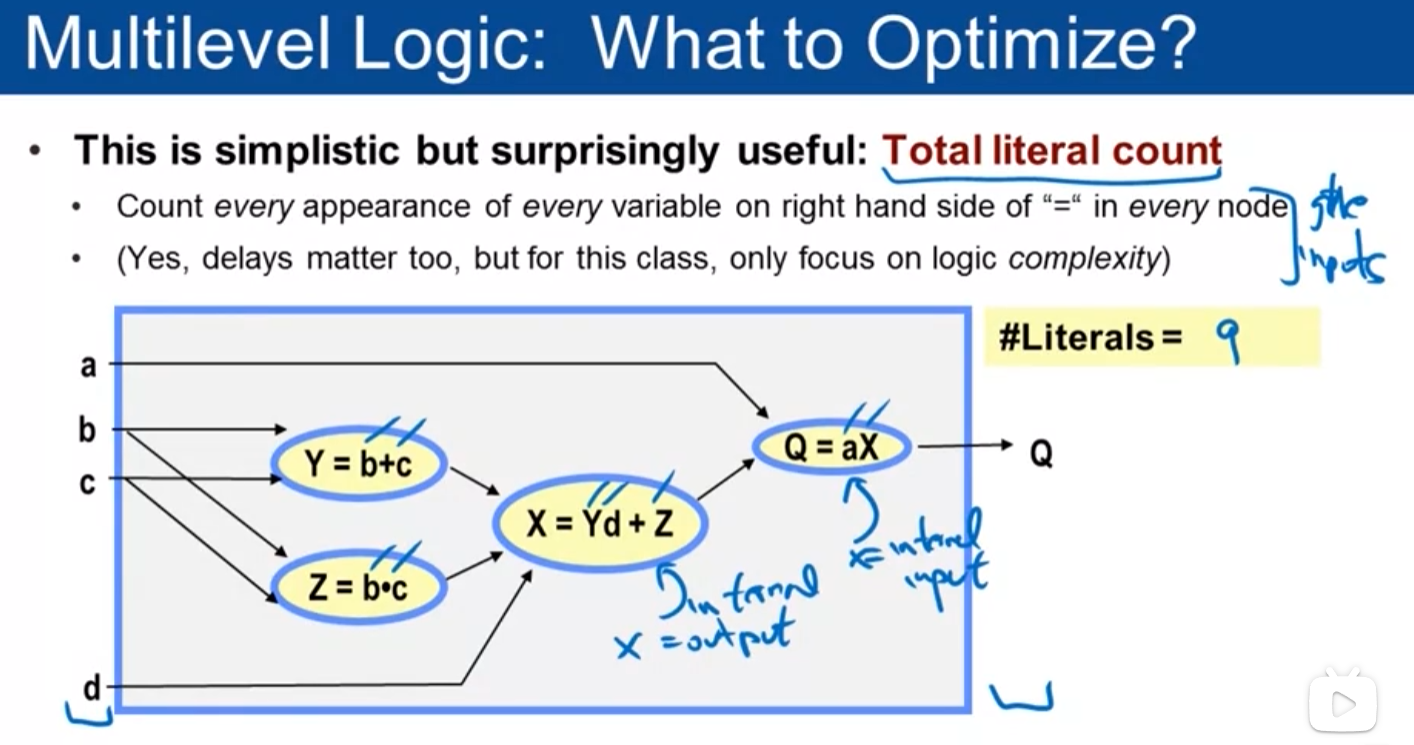
2.1 Literal Count指标
与两级逻辑类似,多级逻辑使用literal count作为复杂度主要指标,但计算方式需要扩展:
- 基本定义:电路中所有变量出现次数的总和(包括原变量和反变量)
- 多级扩展:必须计入中间节点的literal。例如表达式F = (a+b)(c+d)+e:
- 第一级:(a+b)含2 literals,(c+d)含2 literals
- 第二级:将中间结果相乘再加e,又引入3 literals
- 总literal count = 2 + 2 + 3 = 7
2.2 优化策略框架
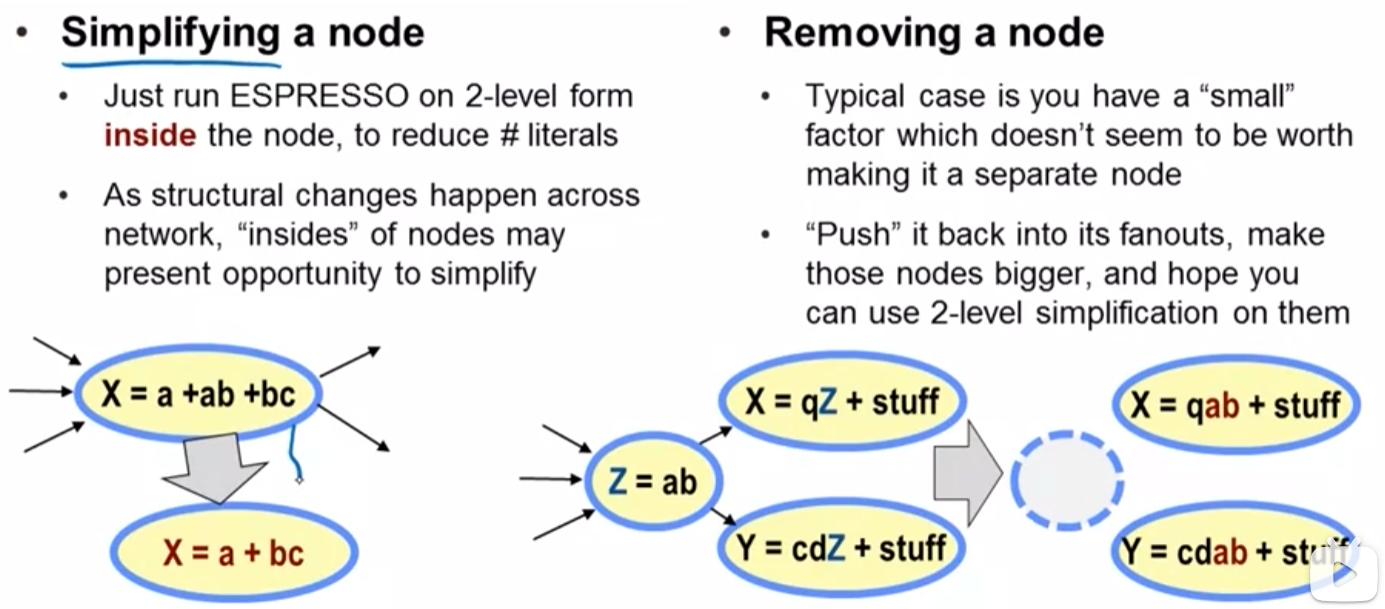
基于literal count指标,我们有三类基本优化手段:
| 策略类型 | 操作方式 | 适用场景 | 优化效果 |
|---|---|---|---|
| 节点简化 | 对单个节点表达式进行代数化简 | 局部表达式复杂度过高 | 降低单个节点literal count |
| 节点移除 | 消除冗余中间节点 | 存在可替代的简单表达式 | 减少层级和总literal数 |
| 节点添加 | 提取公共子表达式作为新节点 | 多个节点存在共同子结构 | 通过共享降低总literal数 |
3. 代数模型与分解技术
3.1 代数模型建立
将布尔代数转换为多项式代数需要遵循特定规则:
- 变量规则:将a和a'视为独立变量(通常用不同符号表示)
- 运算规则:
- AND操作视为乘法
- OR操作视为加法
- 保持分配律、结合律等基本性质
例如:F = ab' + a'c 可表示为 F = aB + Ac(其中B=b', A=a')
3.2 代数除法算法
代数除法是多级分解的基础操作,其伪代码实现要点:
-
输入预处理:
- 确保被除数F无冗余项(如a+ab需简化为a)
- 除数D应为cube-free形式(无公共因子)
-
核心算法步骤:
python复制def algebraic_divide(F, D): Q = universal_set for cube in F: for d_cube in D: if d_cube divides cube: Q = Q ∩ (cube / d_cube) R = F - Q*D return Q, R -
实例演算:
F = axc + axd + axe + bc + bd + de
D = ax + bcode复制Q初始= universal set 处理axc: Q=Q ∩ c → Q=c 处理axd: Q=Q ∩ d → Q=c ∩ d 处理axe: Q=Q ∩ e → Q=c ∩ d ∩ e 处理bc: Q=Q ∩ c → Q=c ∩ d 处理bd: Q=Q ∩ d → Q=c ∩ d 处理de: Q保持不变 最终Q = c + d R = axe + de

4. Kernels理论与应用
4.1 Kernels基本概念
- Cube-free:表达式无法提取出公共因子(如a+bc是cube-free,ab+ac不是)
- Kernel定义:对于F = c·K + R,当K为cube-free时,K称为F的kernel
- Co-kernel:对应的公共因子c
例如:
F = adf + aef + bdf + bef + cdf + cef + g
= (a + b + c)(d + e)f + g
Kernels: {(a+b+c)(d+e)f + g, (a+b+c)(d+e), (d+e)f, d+e}
Co-kernels:
4.2 Brayton-McMullen理论
该理论为寻找最优分解提供了数学基础:
两个表达式F和G存在共同multi-level divisor d,当且仅当存在:
- k1 ∈ K(F)
- k2 ∈ K(G)
使得d = k1 ∩ k2,且d至少包含两个cube
应用案例:
F = a(c+d) + e(c+d) + b
G = a(c+d) + f(c+d) + g
共同kernel: (c+d)
可提取公共因子: (c+d)(a + e) + b 和 (c+d)(a + f) + g
4.3 Kernels提取算法
递归算法实现要点:
-
基础步骤:
- 若F为单cube或无cube,返回空集
- 找出F的所有literal除数
-
递归步骤:
python复制def extract_kernels(F): if F is cube or empty: return ∅ kernels = ∅ for literal in F.literals: D = largest cube dividing F/literal if D is not empty: K = extract_kernels(F/(literal*D)) kernels.add(F/(literal*D)) kernels.update(K) return kernels

5. 除子提取技术
5.1 Single Cube Divisors
提取流程:
-
构建cube-literal矩阵:
- 行:所有不重复的product项
- 列:所有出现的literal
-
矩阵覆盖优化:
- 目标:选择最少数量的行覆盖最多列
- 评估指标:literal saving = Σ(被覆盖列的出现次数-1) - (选择的行数)
示例矩阵:
| a | b | c | d | |
|---|---|---|---|---|
| ab | 1 | 1 | 0 | 0 |
| ac | 1 | 0 | 1 | 0 |
| ad | 1 | 0 | 0 | 1 |
| bc | 0 | 1 | 1 | 0 |
最佳选择:提取a(覆盖a列,saving=3)

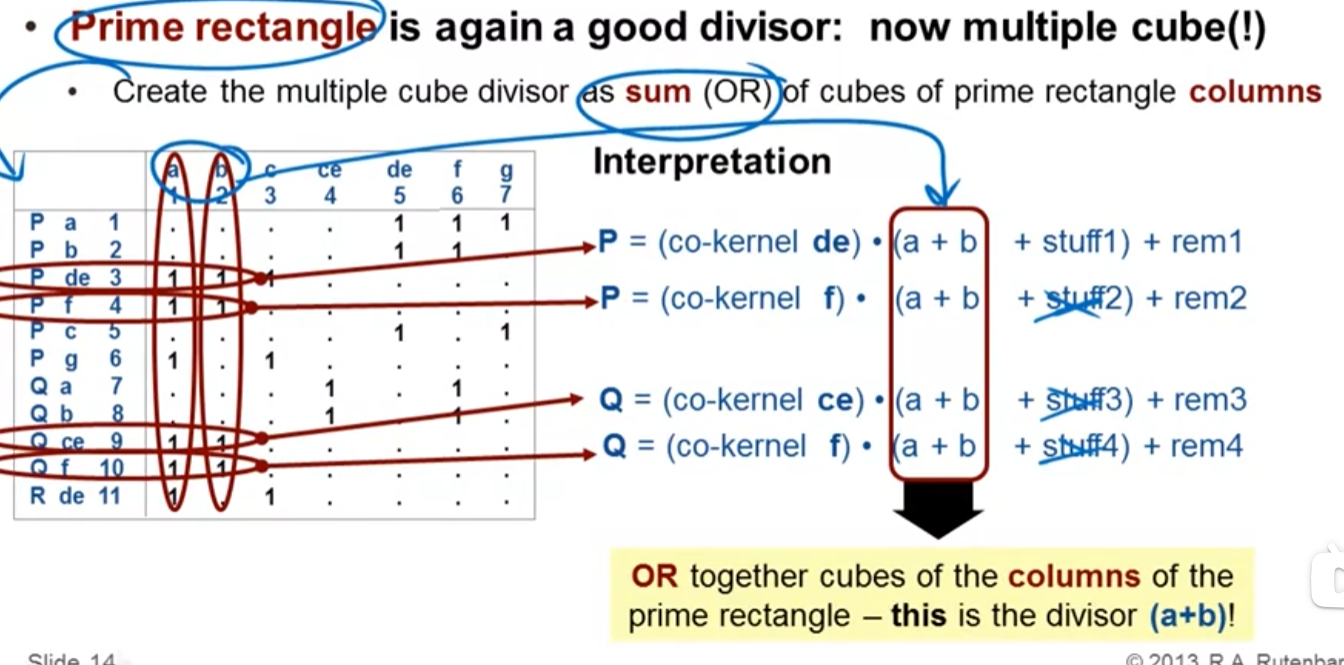
5.2 Multiple Cube Divisors
提取步骤:
-
构建co-kernel cube矩阵:
- 行:所有不重复的kernel
- 列:对应的co-kernel
-
矩阵分析:
- 寻找行间的共同cube模式
- 计算每种组合的literal saving
示例:
F = af + bf + ag + bg + cdf + cef + cg
Kernels: {f+g, a+b, df+ef, c(f+g), ...}
提取(f+g)(a+b) + c(f+g) + cdf
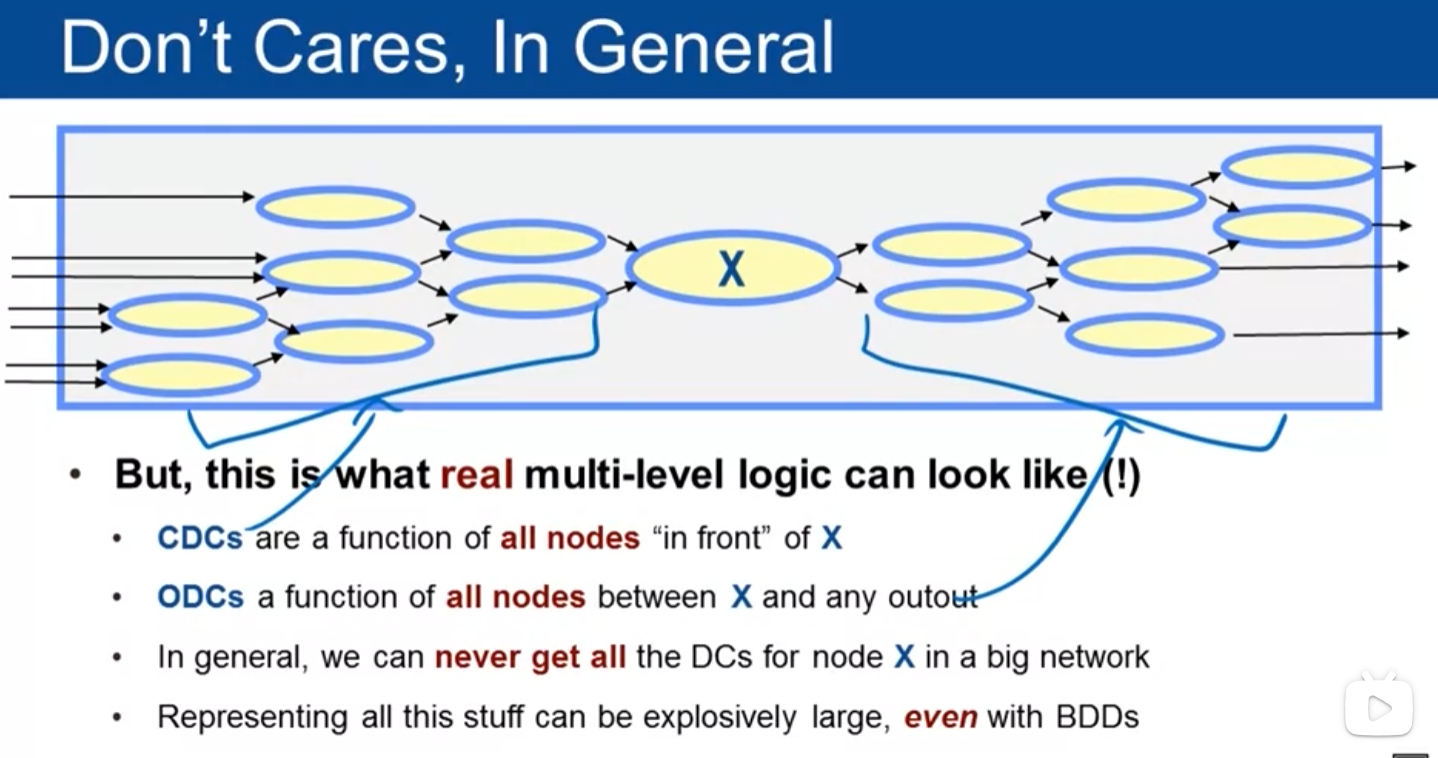
6. Don't Care优化技术
6.1 SDC(可满足性无关项)
计算方式:
SDC_X = X ⊕ F(X的驱动表达式)
示例:
X = a + b
SDC_X = X ⊕ (a + b) = X'(a + b) + X(a + b)'
工程应用:
- 当SDC=1时表示矛盾状态
- 可用于验证逻辑一致性
6.2 CDC(可控性无关项)
计算步骤:
- 计算所有内部节点的SDC
- 对primary input进行全称量词消解
- 结果表示输入不可能出现的模式
示例电路:
code复制a,b → X = a + b
a,b → Y = ab
X,Y → F = X'Y + XY'
CDC_F = (∀b)(SDC_X + SDC_Y) = X'a + X'Y + Ya'
6.3 ODC(可观测性无关项)
计算流程:
- 计算布尔差分∂F/∂X
- 对非X相关变量进行全称量词消解
示例:
F = ab' + a'b
Z = ab + Fc' + F'b'
ODC_F = (∀c)(∂Z/∂F) = (a ⊕ b)'
应用价值:
- 当ODC=1时,F值变化不影响输出
- 可用来简化F的实现
7. 工程实践建议
在实际EDA工具实现中,需要考虑以下工程因素:
-
算法效率优化:
- 对大规模电路采用层次化处理
- 使用hash表加速kernel提取
- 矩阵覆盖问题采用启发式算法
-
时序约束处理:
- 在提取过程中加入时序关键路径权重
- 对时序敏感路径限制逻辑层级
-
物理设计协同:
- 考虑提取后的布局布线影响
- 对高扇出节点进行特殊处理
工具实现技巧:商业工具如Design Compiler会采用"标记-清除"策略,先激进提取再根据约束回退,这种策略能在合理时间内获得近似最优解。
典型优化流程:
- 初始网表建立
- 快速面积优化(基于代数分解)
- 时序驱动优化(考虑Don't Care)
- 增量式改进(局部调整)
- 验证与收敛检查