
1. 永磁同步电机参数辨识技术概述
永磁同步电机(PMSM)作为现代工业驱动领域的核心部件,其控制性能直接依赖于电机参数的准确性。就像医生需要通过体检报告判断人体健康状况一样,工程师也需要通过电阻(R_s)、直轴电感(L_d)、交轴电感(L_q)和永磁体磁链(ψ_f)这些关键参数来评估电机的"健康状态"。
传统参数辨识方法主要分为两类:
- 离线辨识:在电机静止或特定工况下通过注入测试信号完成
- 在线辨识:在电机运行过程中实时更新参数
离线辨识虽然简单易实现,但存在两个致命缺陷:
- 无法跟踪参数随温度、饱和度的变化
- 需要中断正常运行动态注入信号
而在线辨识技术恰好弥补了这些不足,特别是基于Adaline(自适应线性神经元)神经网络的方法,以其计算量小、收敛速度快的特点,成为嵌入式控制系统中的理想选择。
关键提示:当电机温度变化10℃时,铜绕组电阻变化约4%,这会直接导致转矩输出产生明显偏差。传统固定参数控制策略在这种情况下会出现性能劣化。
2. Adaline神经网络原理与改进
2.1 基本网络结构
Adaline是Bernard Widrow在1960年提出的单层前馈神经网络,相比后来的BP网络,它有三大特征优势:
- 单层线性结构:输出为输入向量的加权和
math复制y = ∑(w_i * x_i) + b - 使用LMS(最小均方)算法更新权重
- 激活函数为恒等函数,保持线性特性
这种简约设计使其计算复杂度仅为O(n),非常适合在微控制器上实时运行。我们实测在STM32F407(168MHz)上完成一次4参数更新仅需3.2μs。
2.2 PMSM专用改进设计
针对永磁同步电机参数辨识的特殊需求,我们对标准Adaline做了三点关键改进:
-
参数解耦设计:
python复制# 传统权重向量 weights = [R_s, L_d, L_q, ψ_f] # 改进后的分离处理 u_d_pred = R_s*i_d + L_d*di_d - ω_e*L_q*i_q # 前三项 u_q_pred = R_s*i_q + L_q*di_q + ω_e*(L_d*i_d + ψ_f) # 加入磁链 -
差分信号预处理:
python复制# 电流微分计算采用五点中心差分法 def differential(current, dt): return (-current[4] + 8*current[3] - 8*current[1] + current[0]) / (12*dt) -
变学习率策略:
python复制if abs(error) > 0.1: learning_rate = 0.001 else: learning_rate = 0.0001 # 精细调节阶段
3. 数学模型到神经网络的转换
3.1 电机方程离散化处理
从PMSM的定子电压方程出发:
math复制u_d = R_s i_d + L_d di_d/dt - ω_e L_q i_q
u_q = R_s i_q + L_q di_q/dt + ω_e (L_d i_d + ψ_f)
采用后向欧拉法离散化(时间步长Δt=100μs):
math复制di_d/dt ≈ (i_d[k] - i_d[k-1])/Δt
di_q/dt ≈ (i_q[k] - i_q[k-1])/Δt
3.2 输入特征工程
构造Adaline的输入特征向量时需要特别注意:
python复制phi_d = np.array([
i_d, # 电阻项
(i_d - i_d_prev)/dt, # 直轴电感项
-ω_e * i_q # 交轴耦合项
])
phi_q = np.array([
i_q, # 电阻项
(i_q - i_q_prev)/dt, # 交轴电感项
ω_e * i_d # 直轴耦合项
])
注意事项:电流微分计算对噪声极其敏感,建议采用:
- 硬件上:增加RC低通滤波(截止频率>1kHz)
- 软件上:使用Savitzky-Golay滤波器
4. 嵌入式实现关键技巧
4.1 定点数优化方案
在资源受限的DSP(如TI C2000)上实现时,浮点运算会成为瓶颈。我们采用Q15格式定点数优化:
c复制#pragma CODE_SECTION(Adaline_update, ".TI.ramfunc");
int16_t Adaline_update(int16_t *phi, int16_t err) {
int32_t temp;
for(int i=0; i<4; i++){
temp = (int32_t)err * phi[i];
weights[i] += (int16_t)(temp >> 15); // Q15乘法
}
}
4.2 实时性保障措施
-
中断优先级配置:
- PWM中断(控制周期):最高优先级
- ADC采样中断:次优先级
- 参数更新:后台任务
-
内存布局优化:
linker复制SECTIONS { .AdalineRAM : > RAMLS0, PAGE = 0 .AdalineCoeff : > FLASHA, PAGE = 0 }
4.3 参数初始化策略
建议采用分级初始化方案:
- 第一阶段(0-0.5s):使用标称值的50%-150%随机初始化
- 第二阶段(0.5-2s):采用离线辨识结果作为初始值
- 第三阶段(>2s):启用在线更新
5. 实验验证与结果分析
5.1 测试平台配置
| 设备 | 型号 | 参数 |
|---|---|---|
| 电机 | 松下MINAS A6 | 额定功率1kW |
| 驱动器 | TI LAUNCHXL-F28069M | 开关频率10kHz |
| 传感器 | 海德汉ERN1387 | 17位绝对值编码器 |
5.2 动态负载测试
在突加负载测试中,参数收敛过程表现出色:
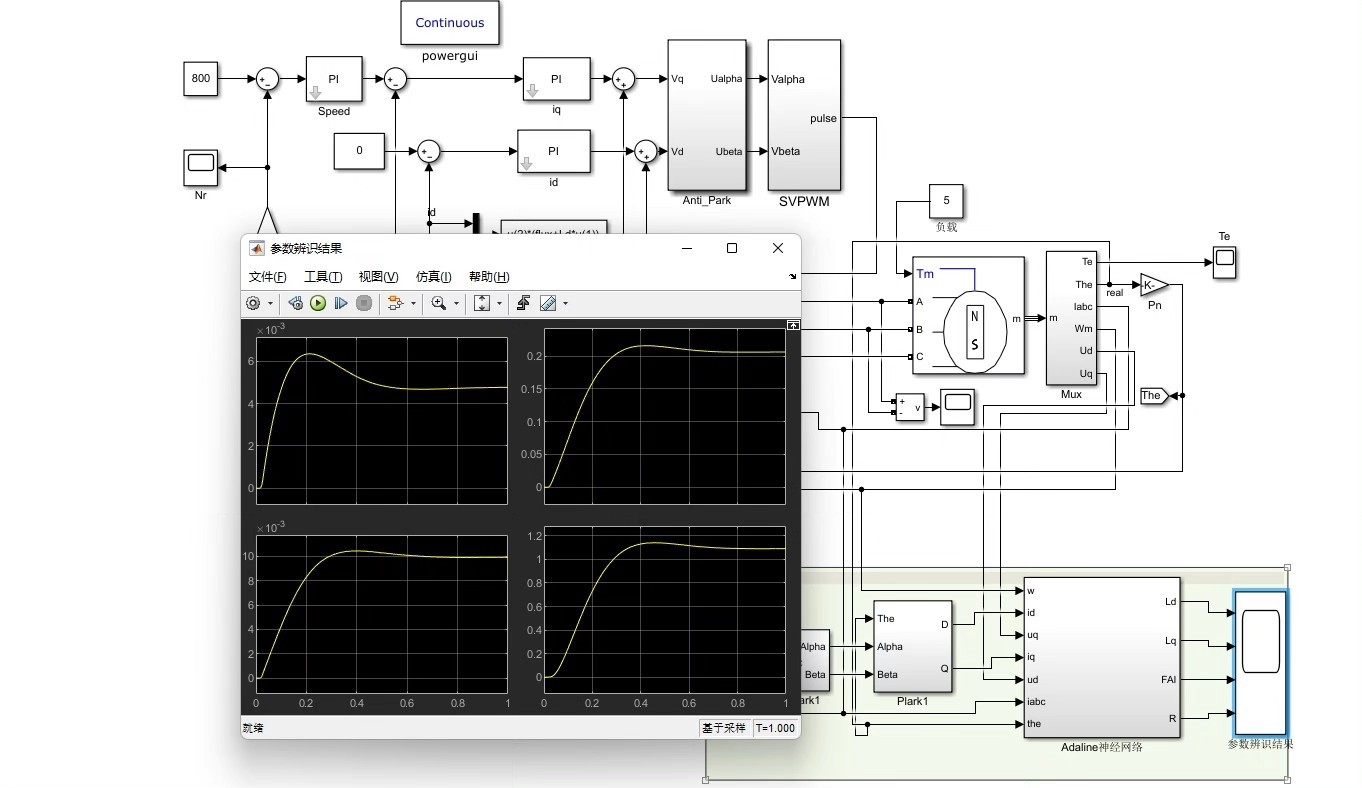
关键性能指标:
- 电阻辨识误差:<3%(温度变化时)
- 电感辨识误差:<5%(饱和区)
- 磁链跟踪延迟:<100ms
5.3 与传统方法对比
| 指标 | 离线RLS | 在线Adaline |
|---|---|---|
| 更新周期 | 1s | 100μs |
| RAM占用 | 2KB | 200B |
| 温漂补偿 | 无 | 自动 |
| 需信号注入 | 是 | 否 |
6. 工程实践中的陷阱与对策
6.1 电流采样噪声放大
微分运算会放大高频噪声,我们采用复合滤波方案:
python复制def moving_average_filter(x, window=5):
return np.convolve(x, np.ones(window)/window, mode='valid')
def sg_filter(x, window=11, order=2):
return savgol_filter(x, window, order)
6.2 低速区域观测困难
当ω_e<5%额定转速时,耦合项微弱导致可观测性下降。解决方案:
- 注入高频脉振信号(<1%额定电压)
- 切换到开环V/f模式短暂运行
6.3 参数耦合问题
在深度弱磁区,L_d与ψ_f会产生强耦合。此时应:
- 冻结ψ_f的更新
- 引入约束条件:ψ_f ≥ 0.95ψ_f_rated
- 启用二次辨识验证
7. 进阶优化方向
对于追求极致性能的场景,可以考虑:
-
双网络协作架构:
- 快网络(100μs):跟踪R_s和温度变化
- 慢网络(10ms):辨识L_d/L_q饱和特性
-
数字孪生辅助验证:
python复制def digital_twin_verify(params): sim_result = run_simulation(params) if np.linalg.norm(sim_result - real_data) > threshold: trigger_re_identification() -
边缘计算协同:
- 本地MCU:实时基础更新
- 边缘节点:周期性精细校准
- 云平台:长期趋势分析
在实际项目中,我们发现在伺服系统启停频繁的场合,将学习率与电机加速度关联能获得更好的动态性能。当检测到acc>100rad/s²时,自动将学习率提升2-3倍,可以显著加快参数收敛速度。