
1. Cortex-M3处理器内核概述
Cortex-M3是ARM公司推出的一款32位RISC处理器内核,专为嵌入式实时应用设计。作为Cortex-M系列中的第二代产品,它在保持低功耗特性的同时,显著提升了处理性能。我曾在多个工业控制项目中采用基于Cortex-M3的芯片,其出色的实时性和能效比给我留下了深刻印象。
1.1 哈佛架构与总线设计
Cortex-M3采用改进型哈佛架构,这种设计在嵌入式领域具有显著优势:
- 独立指令与数据总线:内核通过I-Code和D-Code两条总线并行访问指令和数据,消除了冯·诺依曼架构的瓶颈。在实际项目中,这意味着即使在进行数据搬移时,CPU仍能持续取指,避免了流水线停滞。
- 统一编址空间:虽然采用哈佛架构,但通过总线矩阵实现了4GB统一地址空间。这种设计既保留了哈佛架构的性能优势,又简化了编程模型。我在开发电机控制算法时,这种特性使得DMA传输和CPU执行能够高效并行。
注意:虽然物理总线独立,但编程时仍需注意指令和数据区域的访问权限差异。例如,尝试向Flash区域写入数据将触发硬件错误。
1.2 核心组成部件
拆解内核结构,主要包含四大关键模块:
- Thumb-2指令译码器:支持16位和32位混合指令集,代码密度比纯32位ARM指令提高约30%。在Flash资源受限的场合(如成本敏感型消费电子),这一特性尤为珍贵。
- 三级流水线(取指-译码-执行):通过预取机制实现单周期多数指令执行。但在分支指令时会产生1-2个周期停顿,这在编写实时控制代码时需要特别注意。
- 硬件乘法器:32×32乘法仅需1个周期,64位乘加(MAC)操作也只需3-4周期。我在数字信号处理应用中实测,相比软件模拟实现,性能提升达20倍。
- 寄存器组:包含13个通用寄存器(R0-R12)和3个特殊功能寄存器(SP, LR, PC)。其中R0-R7作为"低寄存器"可被所有Thumb指令访问,这种设计平衡了编码效率和灵活性。

2. 处理器工作模式与存储系统
2.1 双模式与特权分级
Cortex-M3的精妙设计在于其安全机制:
c复制// 典型模式切换示例
void HardFault_Handler(void) {
// 从线程模式自动切换为Handler模式
__asm volatile(
"MRS R0, CONTROL\n"
"BIC R0, #1\n" // 清除nPRIV位
"MSR CONTROL, R0" // 进入特权级
);
}
- 线程模式:运行普通应用程序,可配置为用户级(受限)或特权级
- Handler模式:专用于异常处理,始终处于特权级
我在开发安全固件时,通常将关键驱动放在特权级,而用户应用运行在用户级。当应用需要访问硬件资源时,必须通过受控的系统调用(SVC异常)进入内核服务。
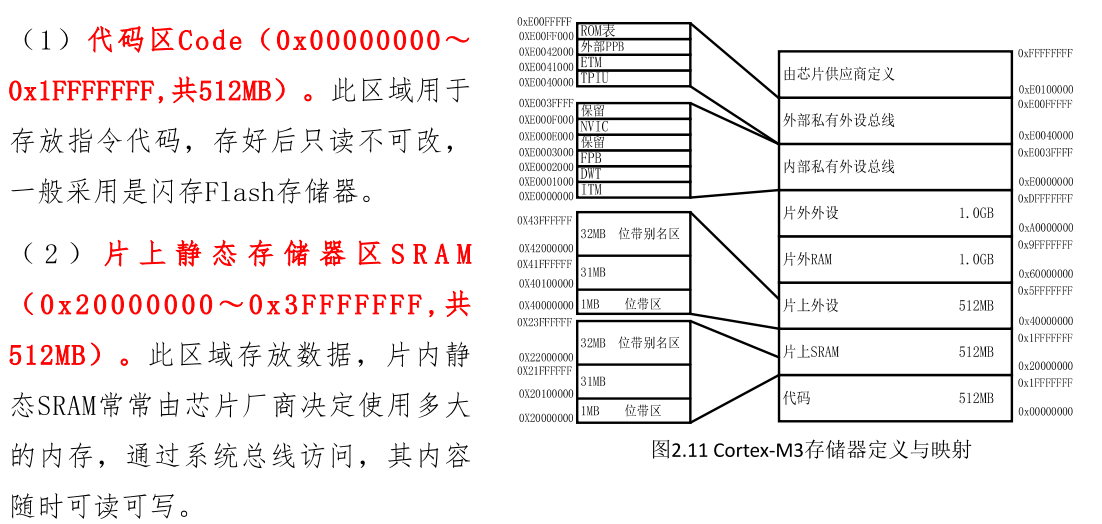
2.2 存储器映射与位带操作
Cortex-M3的存储系统有几个突出特点:
-
4GB统一地址空间:划分为代码、SRAM、外设等区域。例如STM32F103将Flash映射到0x08000000,SRAM在0x20000000。
-
位带别名区:通过将1位映射到32位字实现原子位操作。例如:
c复制#define GPIOA_ODR_BSRR (*(volatile uint32_t*)0x42420000) // PA0的位带别名 GPIOA_ODR_BSRR = 1; // 原子操作设置PA0在开发高实时性IO控制时,这避免了传统的"读-改-写"操作可能引发的竞态条件。
-
存储器保护单元(MPU):可配置8个区域实现访问控制。我在汽车电子项目中用MPU隔离关键数据区,有效防止了程序跑飞导致的系统崩溃。
3. 中断与异常处理机制
3.1 NVIC控制器详解
嵌套向量中断控制器(NVIC)是Cortex-M3实时性的核心:
c复制// 典型中断配置流程
NVIC_SetPriority(USART1_IRQn, 0x03); // 设置优先级为3
NVIC_EnableIRQ(USART1_IRQn); // 使能中断
关键特性包括:
- 256级优先级:实际实现通常只支持8-16级(如STM32用4位实现16级)
- 自动向量获取:硬件直接跳转到中断服务程序(ISR),无需软件判断
- 尾链优化:当两个中断连续发生时,省去多余的出栈/入栈操作
我在通信协议栈开发中实测,NVIC的中断响应延迟最低可达12个周期(约250ns @48MHz),比传统ARM7TDMI快5倍以上。
3.2 异常类型与处理流程
Cortex-M3定义了多种系统异常:
| 异常编号 | 类型 | 典型应用场景 |
|---|---|---|
| 1 | Reset | 系统上电/看门狗复位 |
| 2 | NMI | 电源故障等紧急事件 |
| 3 | HardFault | 所有无法恢复的错误 |
| 4 | MemManage | MPU违规或非法访问 |
| 11 | SVCall | 系统调用接口 |
| 14 | PendSV | 上下文切换(用于RTOS) |
中断响应序列优化:
- 咬尾中断:当ISR1退出时立即进入ISR2,省去恢复现场的冗余操作
- 晚到异常:高优先级中断可抢占正在入栈的低优先级中断
我在RTOS移植中发现,合理使用PendSV异常可显著降低任务切换开销。典型FreeRTOS移植中,上下文切换时间可控制在1.2μs以内(@72MHz)。
4. Cortex-M3应用实践
4.1 低功耗设计技巧
基于个人项目经验,总结以下省电策略:
-
睡眠模式选择:
c复制__WFI(); // 等待中断(保持时钟运行) __WFE(); // 等待事件(可停止时钟)- 在电池供电的传感器节点中,合理使用STOP模式可将功耗降至5μA以下
-
时钟管理:
- 动态调整HCLK(通常设为最大频率的1/2-1/4)
- 外设时钟门控(如禁用未使用的USART时钟)
-
中断唤醒优化:
- 配置EXTI唤醒而非轮询
- 使用RTC闹钟替代软件定时
4.2 调试与故障排查
常见问题及解决方法:
-
HardFault定位:
- 检查LR值确定异常返回地址
- 分析HFSR(HardFault状态寄存器)定位原因
c复制void HardFault_Handler(void) { uint32_t *sp = (uint32_t*)__get_MSP(); uint32_t pc = sp[6]; // 获取故障PC // 通过SWO或串口输出诊断信息 } -
栈溢出防护:
- 使用MPU设置保护页
- 定期检查SP是否越界
-
中断风暴处理:
- 在ISR开始处禁用中断
- 设置看门狗超时
5. Cortex-M3与A系列对比
5.1 架构差异比较
以Cortex-A7为参照:
| 特性 | Cortex-M3 | Cortex-A7 |
|---|---|---|
| 流水线 | 3级 | 8级 |
| 工作模式 | 2种(线程/Handler) | 9种(包括Hyp虚拟化) |
| 内存管理 | 可选MPU | 必需MMU |
| 典型应用 | 实时控制 | 应用处理器 |
| 中断响应 | <12周期 | >20周期 |
5.2 选型建议
根据项目经验给出建议:
-
选择Cortex-M3当:
- 需要确定性实时响应(工业控制)
- 功耗预算严格(穿戴设备)
- 成本敏感(消费电子)
-
选择Cortex-A7当:
- 需要运行Linux等复杂OS
- 涉及多媒体处理
- 要求虚拟化支持
在混合架构设计中(如IoT网关),我常采用M3做实时数据采集,A7运行上层协议栈,通过共享内存实现高效协同。
6. 开发实战建议
6.1 工具链选择
推荐工具组合:
- 编译器:ARMCC(商业版)或GCC-ARM(开源)
- 调试器:J-Link EDU(性价比高)或ST-Link(原厂支持)
- IDE:Keil MDK(易用)或VS Code + Cortex-Debug(灵活)
6.2 性能优化技巧
关键优化手段:
-
指令选择:
- 使用Thumb-2 16位指令优化代码密度
- 避免除法(改用移位或查表)
-
数据对齐:
c复制#pragma pack(push, 4) typedef struct { uint32_t id; uint8_t data[3]; } sensor_pkt; // 强制4字节对齐 #pragma pack(pop) -
缓存友好设计:
- 关键循环控制在16-32条指令内
- 顺序访问数组数据
经过这些优化,我在电机控制算法中实现了从200μs到85μs的执行时间缩减,满足了100kHz PWM控制的需求。