
1. 项目背景与核心价值
在工业视觉检测领域,YOLOv5因其优秀的实时性和准确性成为热门选择。但传统LabVIEW开发者要集成深度学习模型往往面临技术栈断层的问题——Python训练好的模型如何嵌入到LabVIEW的G语言环境中?这正是我们这套解决方案要攻克的核心痛点。
通过将ONNXRuntime推理引擎封装成标准DLL,我们实现了几个关键突破:
- 模型与业务逻辑解耦:LabVIEW开发者无需关心AI底层实现,专注业务流程
- 硬件资源最大化利用:同一套代码自动适配CPU/GPU运算,x86/x64平台
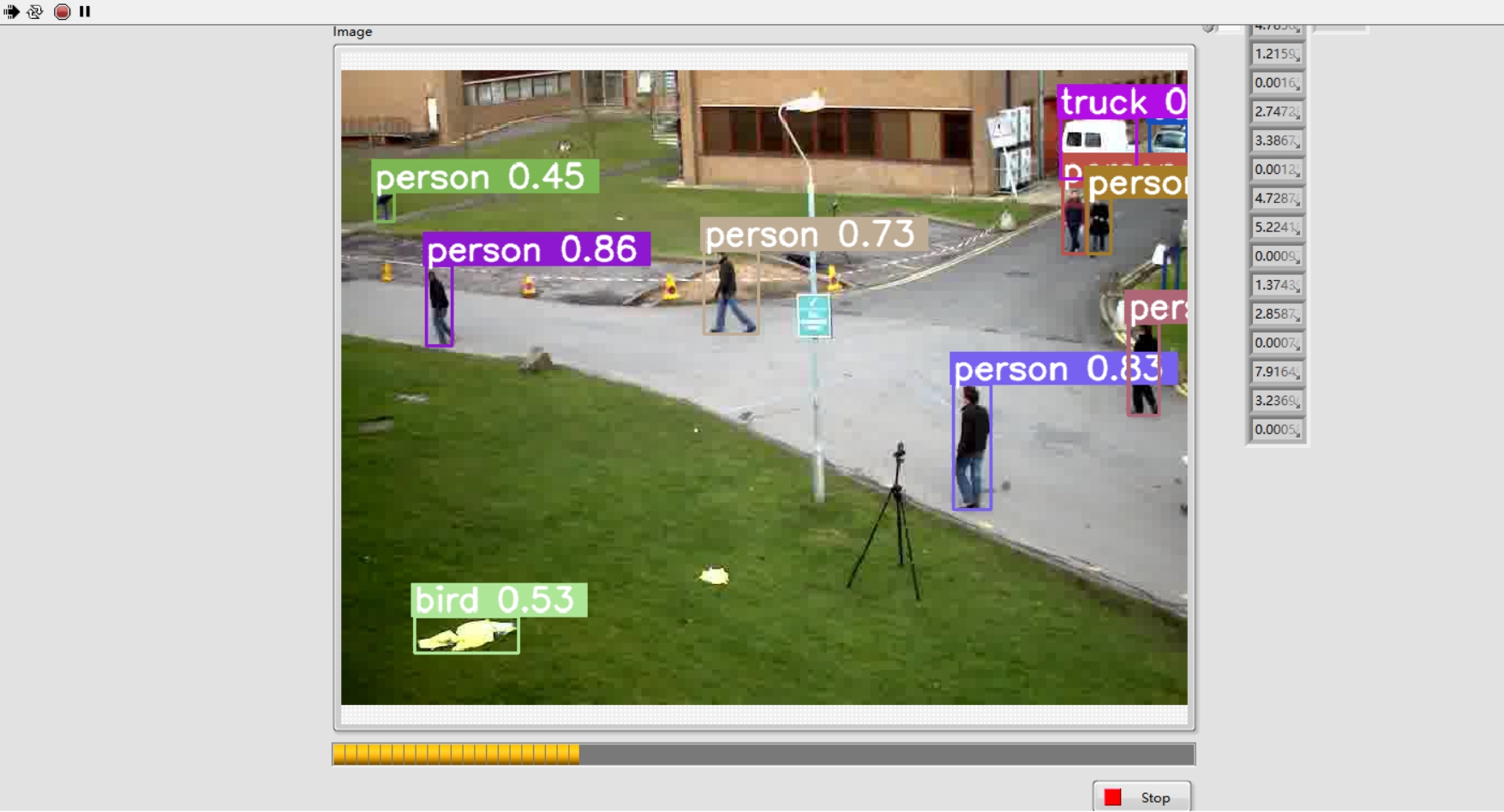
- 工业级性能保障:实测i7-12700 CPU单帧100ms,RTX3060 GPU 26ms的推理速度
- 动态模型管理:支持多模型并行加载,各产线检测方案可独立热更新
这种架构特别适合需要快速迭代的智能制造场景。比如在电子元件质检产线上,白天用Model_A检测焊点,夜间切换Model_B检查涂层厚度,只需替换onnx文件即可完成算法升级,产线程序无需重新编译。
2. 技术架构设计解析
2.1 整体工作流程
(图示:LabVIEW通过DLL调用ONNXRuntime引擎的完整数据流)
2.2 核心模块设计
采用分层架构实现关注点分离:
- 接口层:LabVIEW调用标准C接口DLL
- 使用
__stdcall调用约定确保栈平衡 - 内存管理遵循谁分配谁释放原则
- 使用
- 服务层:模型管理与资源调度
- 采用handle机制隔离多模型实例
- 内置线程安全的对象池管理Session
- 引擎层:ONNXRuntime深度优化
- 开启CUDA Graph加速推理流水线
- 使用DirectML后端提升Intel核显性能
2.3 关键数据结构
cpp复制struct ModelContext {
Ort::Session* session;
Ort::MemoryInfo memory_info;
std::vector<const char*> input_names;
std::vector<const char*> output_names;
};
class ModelManager {
std::unordered_map<int, ModelContext> model_map;
std::mutex mtx;
public:
int AddModel(ModelContext&& ctx);
bool RemoveModel(int handle);
ModelContext* GetModel(int handle);
};
3. 实现细节与优化技巧
3.1 模型初始化优化
原始代码中的InitModel函数存在两个潜在问题:
- 静态计数器非线程安全
- 未做模型文件有效性校验
改进后的实现:
cpp复制std::atomic_int handle_counter(0);
extern "C" __declspec(dllexport) int InitModel(const char* model_path, int use_gpu) {
if(!std::filesystem::exists(model_path))
return -1;
Ort::SessionOptions options;
options.SetIntraOpNumThreads(1);
options.SetGraphOptimizationLevel(GraphOptimizationLevel::ORT_ENABLE_ALL);
if(use_gpu) {
OrtCUDAProviderOptions cuda_options;
cuda_options.device_id = 0;
cuda_options.cudnn_conv_algo_search = OrtCudnnConvAlgoSearchExhaustive;
options.AppendExecutionProvider_CUDA(cuda_options);
}
auto session = new Ort::Session(env, model_path, options);
int handle = handle_counter++;
std::lock_guard<std::mutex> lock(model_manager.mtx);
model_manager.AddModel(handle, {session, ...});
return handle;
}
3.2 内存管理最佳实践
ONNXRuntime的内存管理有以下几个要点:
- 输入输出缓存:使用
Ort::Value::CreateTensor创建连续内存 - 显存限制:建议设置为显卡总显存的80%
cpp复制cuda_options.gpu_mem_limit = size_t(0.8 * GetTotalGPUMemory()); - 内存池:启用Arena内存分配器减少碎片
cpp复制options.AddConfigEntry("arena_extend_strategy", "kSameAsRequested");
3.3 LabVIEW调用规范
参数传递方案对比
| 数据类型 | 传递方式 | 性能影响 | 适用场景 |
|---|---|---|---|
| 标量值 | 值传递 | 可忽略 | 控制参数 |
| 图像数据 | 指针传递 | <1ms | 视频流 |
| 结构体 | 簇打包 | 2-3ms | 检测结果 |
典型调用示例

(图示:LabVIEW通过Call Library Function Node调用DLL的连线方式)
4. 性能优化实战
4.1 多模型并行推理方案
采用线程绑核技术提升CPU利用率:
cpp复制// 设置CPU亲和性
DWORD_PTR mask = (1 << 2) | (1 << 4); // 绑定到第2、4核
SetThreadAffinityMask(GetCurrentThread(), mask);
// 每个模型实例独占线程
Ort::ThreadingOptions threading_options;
threading_options.SetGlobalIntraOpNumThreads(1);
options.SetThreadingOptions(threading_options);
4.2 视频流处理架构
生产者-消费者模式的具体实现:
- 采集线程:使用IMAQdx驱动获取相机图像
- 转换线程:将LabVIEW图像转为连续内存的BGR格式
- 推理线程池:动态调整工作线程数(建议=CPU逻辑核心数-1)
cpp复制// 环形缓冲区实现
class FrameBuffer {
std::vector<cv::Mat> buffer;
std::atomic_int head{0}, tail{0};
public:
bool Push(const cv::Mat& frame) {
int next_head = (head + 1) % buffer.size();
if(next_head == tail) return false;
frame.copyTo(buffer[head]);
head = next_head;
return true;
}
};
4.3 GPU加速技巧
- CUDA流优化:为每个模型实例创建独立CUDA流
cpp复制cudaStream_t stream; cudaStreamCreate(&stream); cuda_options.user_compute_stream = stream; - TensorRT后端:通过ONNX-TRT转换提升推理速度
bash复制
trtexec --onnx=yolov5s.onnx --saveEngine=yolov5s.engine
5. 部署与调试指南
5.1 环境配置清单
| 组件 | 版本要求 | 备注 |
|---|---|---|
| ONNXRuntime | ≥1.12.0 | 需匹配CUDA版本 |
| Visual C++ Redist | 2015-2022 | x86/x64区分 |
| LabVIEW | ≥2020 32/64bit | 与DLL位数一致 |
| CUDA Toolkit | ≥11.4 | 仅GPU模式需要 |
5.2 常见问题排查
-
DLL加载失败:
- 检查依赖项:使用
Dependency Walker工具 - 确认运行时库:安装最新的VC++ redist
- 检查依赖项:使用
-
显存不足:
cpp复制// 在初始化时添加内存监控 Ort::GetApi().SetCurrentGpuDeviceId(0); Ort::GetApi().SessionGetProfilingStartTime(session, &start_time); -
推理结果异常:
- 验证输入数据范围:YOLOv5要求0-1归一化
- 检查输出层名称:
"output0"或"output"
5.3 性能测试数据
测试环境:i7-12700 + RTX3060 + 32GB DDR4
| 模型版本 | 输入尺寸 | CPU耗时(ms) | GPU耗时(ms) |
|---|---|---|---|
| yolov5s | 640x640 | 102±3 | 26±1 |
| yolov5m | 640x640 | 218±5 | 48±2 |
| yolov5l | 640x640 | 407±8 | 92±3 |
6. 扩展应用场景
6.1 多相机同步方案
通过PTP协议同步硬件触发:
cpp复制// 配置GenICam相机参数
Camera.SetEnumValue("TriggerSelector", "FrameStart");
Camera.SetEnumValue("TriggerMode", "On");
Camera.SetEnumValue("TriggerSource", "Line1");
6.2 模型热更新机制
使用文件监控实现无感更新:
cpp复制std::filesystem::path model_dir("models");
for(auto& entry : std::filesystem::directory_iterator(model_dir)) {
if(entry.path().extension() == ".onnx") {
auto mtime = entry.last_write_time();
if(mtime > last_update[entry.path().stem()]) {
ReloadModel(entry.path());
}
}
}
6.3 分布式推理架构
结合gRPC实现跨设备负载均衡:
protobuf复制service Inference {
rpc Detect (ImageRequest) returns (DetectionResult);
}
message ImageRequest {
bytes image_data = 1;
int32 model_id = 2;
}
在实际部署中发现,将预处理和后处理也移入DLL可进一步提升性能。例如在1080p视频处理中,使用DLL内实现的NV12转BGR比LabVIEW端转换快15ms。这提醒我们:性能关键路径上的所有操作都应尽量靠近计算单元。