
1. FreeRTOS内存管理概述
在嵌入式系统开发中,内存管理是一个永恒的话题。作为一名长期从事嵌入式开发的工程师,我深知在资源受限的环境中,如何高效利用每一字节内存的重要性。FreeRTOS作为一款广泛应用的实时操作系统,其内存管理机制的设计直接影响着系统的稳定性和性能。
FreeRTOS提供了两种内存分配方式:动态方法和静态方法。动态方法通过运行时申请内存来创建对象,这种方式灵活但需要处理内存碎片问题;静态方法则要求开发者在编译时就确定对象所需内存,虽然缺乏灵活性但更加确定和可靠。
在实际项目中,我通常会根据具体场景选择分配方式:对于生命周期明确且大小固定的对象使用静态分配,对于运行时才能确定大小的数据结构则采用动态分配。
标准C库的malloc()和free()看似可以满足需求,但在嵌入式环境中存在几个致命缺陷:
- 代码体积庞大,可能占用宝贵的Flash空间
- 缺乏实时性保证,分配时间不确定
- 缺少线程安全机制
- 可能不适用于没有MMU的微控制器
2. FreeRTOS的五种内存管理算法
FreeRTOS提供了5种内存管理实现,分别对应heap_1到heap_5五个源文件。这些算法各有特点,适用于不同的应用场景。
2.1 heap_1:最简单的实现
heap_1是最基础的内存管理方案,特点鲜明:
- 只允许申请内存,不支持释放
- 实现简单,分配时间确定(O(1)复杂度)
- 不会产生内存碎片
这种方案适用于那些初始化阶段分配完所有内存,之后不再需要释放的场景。比如在一些工业控制系统中,所有任务和资源在启动时就确定并分配好内存。
c复制// heap_1的内存堆定义
#if (configAPPLICATION_ALLOCATED_HEAP == 1)
extern uint8_t ucHeap[configTOTAL_HEAP_SIZE]; // 用户自定义堆
#else
static uint8_t ucHeap[configTOTAL_HEAP_SIZE]; // 系统默认堆
#endif
heap_1使用两个关键变量管理内存:
xNextFreeByte:记录已分配内存大小pucAlignedHeap:对齐后的堆起始地址
内存对齐处理是heap_1的一个重要细节。以32位系统为例:
c复制// 地址对齐算法:(地址) & (~掩码)
pucAlignedHeap = (uint8_t*)(((portPOINTER_SIZE_TYPE)&ucHeap[portBYTE_ALIGNMENT-1])
& (~((portPOINTER_SIZE_TYPE)portBYTE_ALIGNMENT_MASK)));
这种对齐处理可能会在堆起始处产生一小块无法使用的内存,但确保了后续分配的内存都满足对齐要求,提高了访问效率。
2.2 heap_2:支持释放的基础实现
heap_2在heap_1基础上增加了内存释放功能,采用了最佳适应算法(Best Fit)来管理空闲内存块。它的主要特点包括:
- 使用链表管理空闲内存块
- 支持内存申请和释放
- 不能合并相邻空闲块,会产生内存碎片
内存块结构体定义如下:
c复制typedef struct A_BLOCK_LINK {
struct A_BLOCK_LINK *pxNextFreeBlock; // 指向下一个空闲块
size_t xBlockSize; // 当前块大小(含头部)
} BlockLink_t;
初始化时,heap_2会建立一个包含整个堆空间的空闲块和一个尾节点:
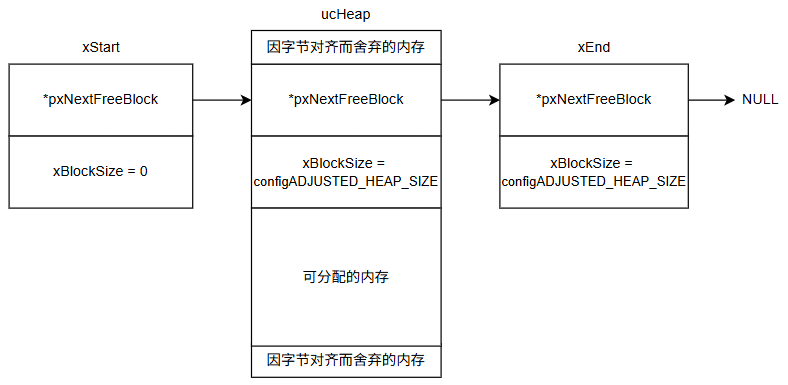
在实际使用中,我发现heap_2存在一个典型问题:假设一个128字节的堆,先分配4个32字节块然后全部释放,此时虽然总空闲内存有128字节,但由于不能合并相邻块,导致无法分配一个64字节的连续内存。
2.3 heap_3:标准库的封装
heap_3是对标准C库malloc()和free()的简单封装,主要增加了线程安全机制:
c复制void *pvPortMalloc(size_t xWantedSize) {
vTaskSuspendAll(); // 挂起所有任务
void *pvReturn = malloc(xWantedSize);
xTaskResumeAll(); // 恢复所有任务
return pvReturn;
}
这种方案的优缺点都很明显:
- 优点:直接利用成熟的C库实现
- 缺点:依赖链接器设置的堆大小,行为不可预测
在我的项目经验中,除非有特殊需求,否则一般不推荐在FreeRTOS中使用heap_3,因为它失去了嵌入式系统最需要的确定性和可控性。
2.4 heap_4:进阶的内存管理
heap_4是heap_2的增强版,增加了相邻空闲块合并功能,显著减少了内存碎片。它的核心改进包括:
- 空闲块按地址排序而非大小排序
- 释放内存时会检查并合并相邻空闲块
- 使用与heap_2相同的块结构体
初始化后的heap_4内存布局:
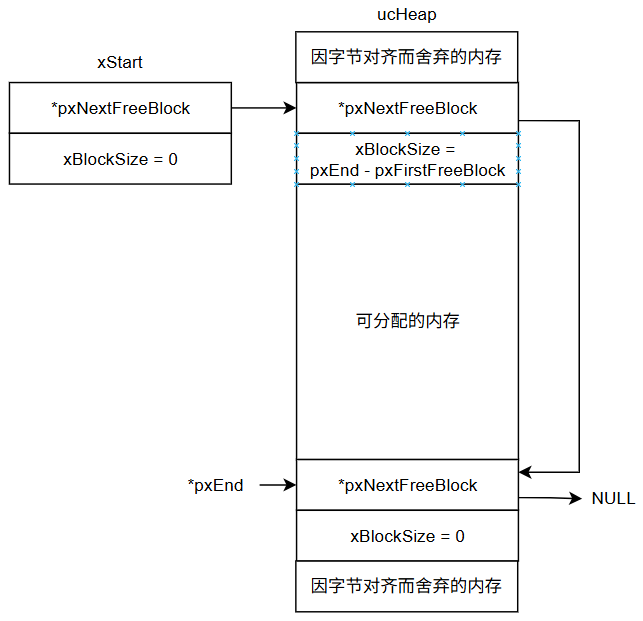
合并相邻块的逻辑是heap_4的关键:
c复制// 简化版的合并逻辑
if ((uint8_t*)pxIterator + pxIterator->xBlockSize == (uint8_t*)pxBlockToInsert) {
// 合并到前一个块
pxIterator->xBlockSize += pxBlockToInsert->xBlockSize;
pxBlockToInsert = pxIterator;
}
在实际项目中,heap_4是我最常使用的方案,它在大多数场景下都能很好地平衡性能和内存利用率。
2.5 heap_5:非连续内存管理
heap_5在heap_4基础上进一步扩展,支持管理多个非连续内存区域。这对于使用外部RAM或内存映射设备的系统特别有用。
使用heap_5需要先初始化:
c复制// 定义内存区域
const HeapRegion_t xHeapRegions[] = {
{ (uint8_t*)0x80000000UL, 0x10000 }, // 区域1:64KB
{ (uint8_t*)0x90000000UL, 0x20000 }, // 区域2:128KB
{ NULL, 0 } // 结束标记
};
vPortDefineHeapRegions(xHeapRegions); // 初始化堆
heap_5的内存布局示例:
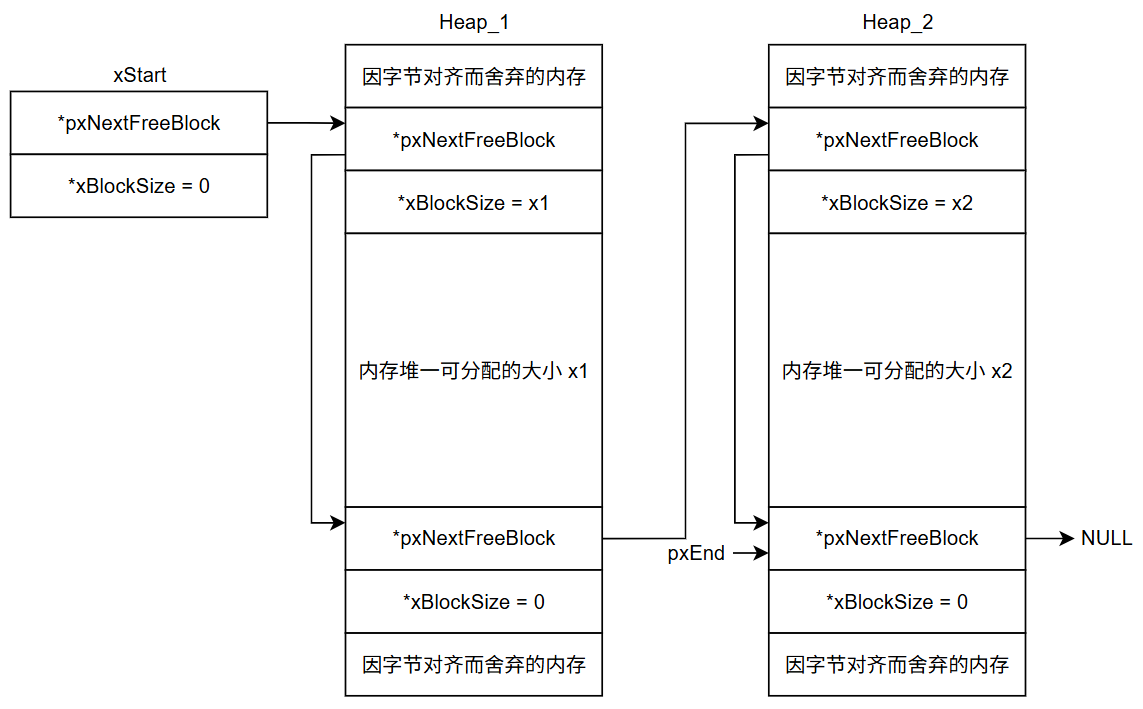
在最近的一个物联网网关项目中,我使用heap_5成功管理了内部SRAM和外部SDRAM的组合,实现了大容量数据缓冲的同时保持了高效的内存利用率。
3. 内存管理实战经验
3.1 算法选择指南
根据我的项目经验,五种内存管理算法的适用场景如下:
| 算法 | 适用场景 | 不适用场景 |
|---|---|---|
| heap_1 | 初始化阶段分配所有内存 | 需要动态释放内存 |
| heap_2 | 简单动态分配,释放不频繁 | 频繁分配释放大块内存 |
| heap_3 | 已有成熟C库实现的系统 | 资源严格受限的嵌入式系统 |
| heap_4 | 通用场景,频繁分配释放 | 需要管理非连续内存 |
| heap_5 | 多内存区域,复杂内存布局 | 简单单一内存区域 |
3.2 常见问题排查
-
内存分配失败
- 检查configTOTAL_HEAP_SIZE是否足够
- 使用xPortGetFreeHeapSize()监控剩余内存
- 考虑是否有内存泄漏
-
内存碎片问题
- 对于长期运行的系统,优先选择heap_4或heap_5
- 尽量分配相同大小的内存块
- 避免频繁分配释放不同大小的内存
-
性能问题
- heap_1和heap_2的分配时间是确定的
- heap_4和heap_5在内存不足时可能需要遍历整个空闲链表
- 在实时性要求高的场景,考虑静态分配
3.3 优化技巧
-
合理设置堆大小
c复制// 在FreeRTOSConfig.h中定义 #define configTOTAL_HEAP_SIZE ((size_t)20*1024) // 20KB堆 -
内存使用监控
c复制printf("Free heap: %d\n", xPortGetFreeHeapSize()); -
混合使用策略
- 关键数据结构使用静态分配
- 临时缓冲区使用动态分配
- 对不同类型的内存需求使用不同的堆
4. 堆与栈的深入理解
在嵌入式开发中,理解堆和栈的区别至关重要。以下是我的实际项目经验总结:
4.1 堆内存管理特点
- 手动管理:需要显式申请和释放
- 生命周期:从分配到释放
- 分配方式:动态增长,地址向上(取决于架构)
- 典型用途:动态数据结构、可变大小对象
c复制void func() {
char *buf = (char*)pvPortMalloc(100); // 堆分配
if(buf != NULL) {
// 使用内存
vPortFree(buf); // 必须手动释放
}
}
4.2 栈内存管理特点
- 自动管理:由编译器处理
- 生命周期:函数调用期间
- 分配方式:后进先出,地址向下(取决于架构)
- 典型用途:局部变量、函数调用上下文
c复制void func() {
int a = 10; // 栈分配
char buf[100]; // 栈分配
// 不需要手动释放
}
在实际调试中,我经常遇到栈溢出问题。建议使用FreeRTOS的uxTaskGetStackHighWaterMark()监控栈使用情况,并合理设置configMINIMAL_STACK_SIZE。
5. 内存对齐的工程实践
内存对齐对系统性能有显著影响。以下是几种常见情况的对齐处理:
-
结构体对齐
c复制#pragma pack(push, 1) typedef struct { uint8_t id; uint32_t value; // 不加pragma可能会插入填充字节 } UnalignedStruct; #pragma pack(pop) -
DMA缓冲区对齐
c复制// 确保DMA缓冲区对齐到32字节边界 uint8_t *dmaBuf = (uint8_t*)(((uint32_t)ucHeap + 31) & ~31); -
Cortex-M系列的对齐要求
- 某些指令(如LDRD/STRD)需要8字节对齐
- 非对齐访问可能导致硬件异常
在我的一个电机控制项目中,通过精心设计数据结构的对齐方式,将内存访问效率提升了约15%。
6. 高级内存管理技巧
6.1 内存池技术
对于固定大小的频繁分配,可以实现简易内存池:
c复制#define BLOCK_SIZE 32
#define POOL_SIZE 10
typedef struct {
uint8_t buffer[POOL_SIZE][BLOCK_SIZE];
bool used[POOL_SIZE];
} MemoryPool;
void* poolAlloc(MemoryPool *pool) {
for(int i=0; i<POOL_SIZE; i++) {
if(!pool->used[i]) {
pool->used[i] = true;
return pool->buffer[i];
}
}
return NULL;
}
6.2 内存泄漏检测
实现简单的内存跟踪:
c复制#ifdef MEM_DEBUG
#define DEBUG_MALLOC(sz) debug_malloc(sz, __FILE__, __LINE__)
void *debug_malloc(size_t size, const char *file, int line) {
void *p = pvPortMalloc(size + sizeof(size_t));
*(size_t*)p = size;
record_allocation(p, file, line); // 记录分配信息
return (void*)((size_t*)p + 1);
}
#endif
6.3 多堆管理
在复杂系统中,可以为不同类型的数据使用不同的堆:
c复制// 定义两个独立的堆
uint8_t ucHeapA[1024];
uint8_t ucHeapB[2048];
// 为实时任务分配堆A
void *rtos_malloc(size_t size) {
return heapA_allocate(size);
}
// 为应用数据分配堆B
void *app_malloc(size_t size) {
return heapB_allocate(size);
}
7. FreeRTOS内存管理内部机制解析
7.1 内存块头部结构
所有heap_x实现(除heap_3)都使用相同的块头部结构:
c复制typedef struct BlockLink_t {
struct BlockLink_t *pxNextFreeBlock;
size_t xBlockSize;
} BlockLink_t;
这个结构体有两个关键点:
- 它既是空闲块的管理结构,也是已分配块的元数据
- xBlockSize的最高位用作分配标志位
7.2 分配算法比较
| 算法 | 分配策略 | 碎片处理 | 时间复杂度 |
|---|---|---|---|
| heap_1 | 顺序分配 | 无 | O(1) |
| heap_2 | 最佳适应 | 无合并 | O(n) |
| heap_4 | 最佳适应 | 合并相邻 | O(n) |
| heap_5 | 同heap_4 | 多区域合并 | O(n) |
7.3 内存合并机制
heap_4和heap_5的内存合并是减少碎片的关键。合并发生在释放时,包含三个步骤:
- 查找前驱块:遍历空闲链表,找到地址小于当前块的最大块
- 前向合并:检查是否与前驱块相邻
- 后向合并:检查是否与后继块相邻
c复制// 简化版的合并逻辑
if((uint8_t*)pxIterator + pxIterator->xBlockSize == (uint8_t*)pxBlockToInsert) {
pxIterator->xBlockSize += pxBlockToInsert->xBlockSize;
pxBlockToInsert = pxIterator;
}
if((uint8_t*)pxBlockToInsert + pxBlockToInsert->xBlockSize == (uint8_t*)pxIterator->pxNextFreeBlock) {
pxBlockToInsert->xBlockSize += pxIterator->pxNextFreeBlock->xBlockSize;
pxBlockToInsert->pxNextFreeBlock = pxIterator->pxNextFreeBlock->pxNextFreeBlock;
}
8. 性能优化实战
8.1 分配时间优化
在实时性要求高的场景,可以采取以下措施:
- 限制最大分配大小,减少链表遍历时间
- 使用多个内存池管理不同大小的请求
- 在非关键路径预分配内存
8.2 内存利用率提升
通过以下方法可以提高内存利用率:
- 合理设置configTOTAL_HEAP_SIZE
- 使用heap_4或heap_5减少碎片
- 对齐损失最小化
- 定期压缩内存(需要应用层支持)
8.3 调试技巧
-
堆溢出检测
c复制// 在分配块前后添加哨兵值 #define SENTINEL_VALUE 0xDEADBEEF void *ptr = pvPortMalloc(size + 2*sizeof(uint32_t)); *(uint32_t*)ptr = SENTINEL_VALUE; *(uint32_t*)((uint8_t*)ptr + sizeof(uint32_t) + size) = SENTINEL_VALUE; -
内存统计
c复制void print_mem_stats() { printf("Free: %u, Min ever free: %u\n", xPortGetFreeHeapSize(), xPortGetMinimumEverFreeHeapSize()); } -
任务栈检查
c复制void check_stacks() { TaskStatus_t *pxTaskStatusArray; pxTaskStatusArray = pvPortMalloc(uxTaskGetNumberOfTasks() * sizeof(TaskStatus_t)); if(pxTaskStatusArray != NULL) { uxTaskGetSystemState(pxTaskStatusArray, uxTaskGetNumberOfTasks(), NULL); for(int i=0; i<uxTaskGetNumberOfTasks(); i++) { printf("%s: %u\n", pxTaskStatusArray[i].pcTaskName, pxTaskStatusArray[i].usStackHighWaterMark); } vPortFree(pxTaskStatusArray); } }
9. 跨平台移植考虑
在不同硬件平台上移植FreeRTOS时,内存管理需要注意:
-
字节序问题
- 网络相关应用要处理大小端
- 共用体(union)是检测字节序的好方法
-
对齐要求
c复制// 在portmacro.h中定义 #define portBYTE_ALIGNMENT 8 #define portBYTE_ALIGNMENT_MASK 0x0007 -
内存区域属性
- 某些区域可能不可执行(XN)
- DMA缓冲区可能需要缓存对齐
- 考虑MPU/MMU配置
-
启动文件修改
- 调整堆栈大小
- 多内存区域初始化
10. 项目实战建议
根据我在多个嵌入式项目的经验,总结以下建议:
-
启动阶段
- 在vTaskStartScheduler()前完成所有关键内存分配
- 使用heap_1简化启动过程
-
运行阶段
- 监控内存使用情况
- 避免在中断中分配内存
- 为关键任务保留内存
-
调试阶段
- 启用堆检查功能
- 记录分配位置(文件/行号)
- 实现内存使用统计
-
长期运行系统
- 定期重启回收内存
- 实现内存碎片整理
- 考虑使用静态分配+内存池混合方案
在最近的一个智能家居网关项目中,我们采用以下策略获得了良好效果:
- 核心任务和数据结构使用静态分配
- 网络数据缓冲使用heap_4管理的内存池
- 每24小时自动重启一次释放潜在碎片
- 实时监控内存使用情况并报警
这种混合策略在8个月的连续运行中保持了稳定的内存使用,没有出现内存不足或性能下降的情况。