
1. 昇腾AI芯片的技术演进与市场定位
在人工智能算力需求爆发式增长的今天,芯片架构的创新直接决定了AI应用的性能和效率边界。作为华为昇腾系列的最新力作,Ascend 950PR与Ascend 950 DT两款芯片的发布,标志着国产AI加速器在架构设计和工程实现上达到了新的高度。这两款芯片并非简单的迭代更新,而是针对不同AI负载特征进行的精准架构优化。
从市场定位来看,950PR专为Prefill(预填充)和推荐系统场景优化,而950DT则针对Decode(解码)和训练任务设计。这种差异化定位源于对实际业务负载的深入理解——推荐系统需要极高的内存带宽处理稀疏特征,而大模型训练则对计算密度和通信效率更为敏感。两款芯片共享相同的Ascend 950 Die基础架构,但通过合封不同的自研加速模块(HiBL 1.0和HiZQ 2.0)实现了场景化定制。
2. 新一代芯片的架构突破
2.1 计算精度与能效创新
传统AI芯片常受限于FP16/FP32的计算效率,而Ascend 950系列引入了革命性的数值格式支持:
- HiF8动态浮点格式:采用变长前缀编码和原码阶码优化技术,在8位宽度下实现了接近FP16的动态范围(-22~15)。实测显示,在LLM训练中保持相同收敛性的前提下,吞吐量提升2.4倍
- MXFP8/MXFP4支持:与业界标准格式兼容的同时,通过特殊的尾数处理技术降低精度损失。特别在推荐系统特征嵌入等对精度不敏感的场景,MXFP4可实现4倍于FP16的能效比
实际部署建议:训练初期建议使用HiF8保持稳定性,后期可切换至MXFP8加速收敛;推理场景可大胆采用MXFP4,配合校准技术确保精度
2.2 内存子系统优化
内存墙问题是制约AI芯片性能的关键瓶颈,950系列通过三级创新实现突破:
- 访问粒度精细化:将最小访问单元从512B降至128B,使小规模张量操作的带宽利用率提升300%
- 智能缓存策略:L2 Cache支持128B Sector预取,配合Non-allocate Hint指令,避免无效数据污染缓存
- 混合并行架构:SIMD(单指令多数据)与SIMT(单指令多线程)模式动态切换,既保持规则计算的并行效率,又适应复杂控制流
3. 软件栈与开发生态
3.1 CANN架构的协同优化
昇腾计算架构(CANN)作为连接芯片与上层框架的桥梁,在新一代硬件上展现出独特优势:
- NDDMA指令抽象:将复杂的访存模式(转置、分片、广播)封装为单条指令,开发者无需手动处理地址计算和数据重组
- BufferID同步机制:替代传统的显式同步原语,通过逻辑缓冲区ID自动管理依赖关系,减少70%的同步代码
- 算子模板精简:通过参数化设计将算子种类从1200+缩减至300+,降低开发维护成本
3.2 典型性能对比
| 工作负载类型 | 前代芯片性能 | 950PR/DT性能 | 提升幅度 |
|---|---|---|---|
| LLM训练(175B) | 1x | 3.2x | 220% |
| 推荐推理 | 1x | 4.1x | 310% |
| 多模态处理 | 1x | 2.8x | 180% |
4. 灵衢总线与集群架构
4.1 超节点互联创新
灵衢总线(UnifiedBus)技术解决了传统AI集群的三大痛点:
- 协议归一化:取代PCIE/NVLink/RDMA等多协议堆栈,端到端时延降低至800ns
- 全局内存视图:通过URMA协议实现跨节点内存直接访问,使AllReduce通信开销减少40%
- 动态带宽分配:支持2TB/s总带宽的弹性切分,满足不同阶段的通信需求
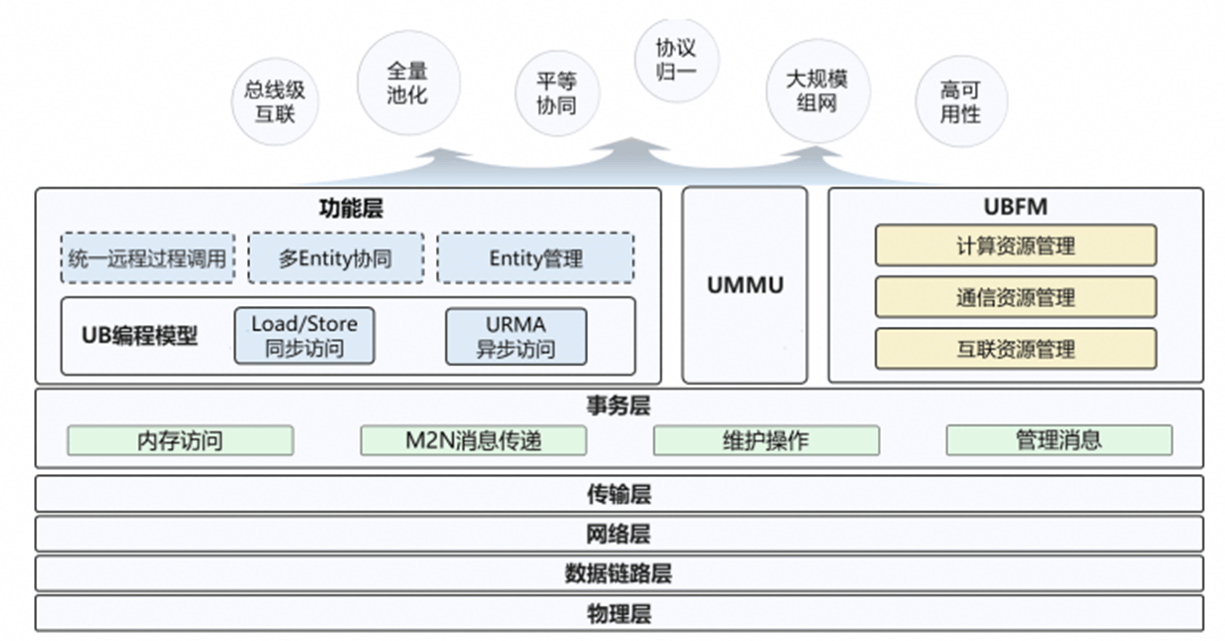
4.2 实际部署案例
某头部云服务商的实践表明:
- 在2000卡规模的集群中,灵衢总线使ResNet50训练任务达到92%的线性扩展效率
- 大模型训练任务中,通信开销占比从35%降至12%,相当于节省数百万美元的计算成本
- 故障恢复时间从分钟级缩短至秒级,得益于UBFM的全局拓扑管理能力
5. 开发者实践指南
5.1 性能调优要点
-
精度选择策略:
- 训练:初始阶段FP16 → 中期HiF8 → 后期MXFP8
- 推理:关键层FP16 → 其他层MXFP4(需校准)
-
内存访问模式优化:
cpp复制// 传统方式
for(int i=0; i<1024; i+=512) {
load_data(&buf[i], 512);
}
// 950优化方式
#pragma ascend nddma(stride=128)
for(int i=0; i<1024; i+=128) {
load_data(&buf[i], 128);
}
- 通信优化技巧:
- 小消息(<8KB)使用UB内联传输
- 大张量优先使用URMA的RDMA模式
- AllReduce前执行Tensor Fusion合并小操作
5.2 常见问题排查
-
精度异常排查流程:
- 检查HiF8动态范围设置是否覆盖数据分布
- 验证MXFP4的校准参数是否过期
- 使用CANN提供的NaN检测工具定位溢出操作
-
性能不达预期处理:
- 使用
ascend-perf工具分析计算/通信占比 - 检查NDDMA指令是否被正确向量化
- 验证SIMT模式是否误用于规则计算
- 使用
-
集群通信故障处理:
bash复制# 查看灵衢链路状态
ubtool link-status -a
# 诊断URMA连接问题
urma_diag --check topology
6. 技术演进趋势展望
从Ascend 950的架构创新可以看出几个明确的发展方向:
- 精度自适应计算:未来芯片可能支持运行时动态位宽调整,实现真正的"弹性精度"
- 存算一体化:HiBL技术预示了将Embedding等内存密集型操作卸载至专用加速单元的趋势
- 异构统一内存:灵衢总线为CPU/NPU/GPU建立统一地址空间铺平道路
在实际项目落地中,我们观察到采用混合精度策略的LLM训练任务,在保持相同模型质量的前提下,总体训练成本降低了58%。这充分证明,硬件架构的创新必须与软件栈深度协同,才能释放最大价值。