
1. 计算机系统中的速度鸿沟问题
现代计算机系统中存在一个根本性的矛盾:CPU的运算速度与外设的工作速度之间存在巨大的差异。以典型的3GHz主频CPU为例,每个时钟周期仅需0.33纳秒,而机械硬盘的寻道时间通常在毫秒级别(1毫秒=1,000,000纳秒),两者速度相差数百万倍。这种速度差异如果处理不当,将导致CPU大部分时间都在等待外设响应,造成严重的资源浪费。
1.1 速度差异的具体表现
在计算机系统中,不同组件的典型操作延迟如下表所示:
| 组件类型 | 典型操作 | 延迟时间 | 与CPU时钟周期比 |
|---|---|---|---|
| CPU寄存器 | 寄存器访问 | 0.3-1ns | 1-3个周期 |
| 高速缓存 | L1缓存访问 | 1-3ns | 3-9个周期 |
| 主内存 | DRAM访问 | 50-100ns | 150-300周期 |
| SSD存储 | 随机读取 | 10-100μs | 30,000-300,000周期 |
| 机械硬盘 | 寻道时间 | 1-10ms | 3,000,000-30,000,000周期 |
| 网络设备 | 跨机房RTT | 10-100ms | 30,000,000-300,000,000周期 |
这种速度差异导致了几个关键问题:
- CPU如果直接与外设交互,99%以上的时间都在等待
- 高速的CPU和内存资源被低速外设拖累
- 系统整体吞吐量受限于最慢的外设
1.2 I/O接口的诞生背景
为了解决这个问题,计算机系统引入了I/O接口(Input/Output Interface)作为CPU与外设之间的"中间人"。I/O接口的主要作用包括:
- 速度缓冲:通过数据缓冲区匹配CPU和外设的速度差异
- 协议转换:将外设的电气信号转换为CPU可理解的数字信号
- 电气隔离:保护CPU免受外设电气特性的影响
- 设备管理:提供统一的访问接口,简化CPU操作
在实际硬件实现中,现代计算机的I/O接口通常集成在南桥芯片中。南桥芯片通过PCIe等高速总线与CPU通信,同时提供USB、SATA、以太网等多种外设接口。这种设计使得CPU可以专注于计算任务,而将外设管理的复杂性交给专门的芯片处理。
2. I/O接口的核心工作机制
2.1 I/O接口的基本结构
一个典型的I/O接口包含以下几个关键组件:
- 数据寄存器:临时存储传输中的数据
- 状态寄存器:反映外设当前状态(就绪/忙/错误等)
- 控制寄存器:接收CPU发送的控制命令
- 地址解码逻辑:识别CPU发来的访问请求
- 中断控制逻辑:管理中断信号的产生和传递
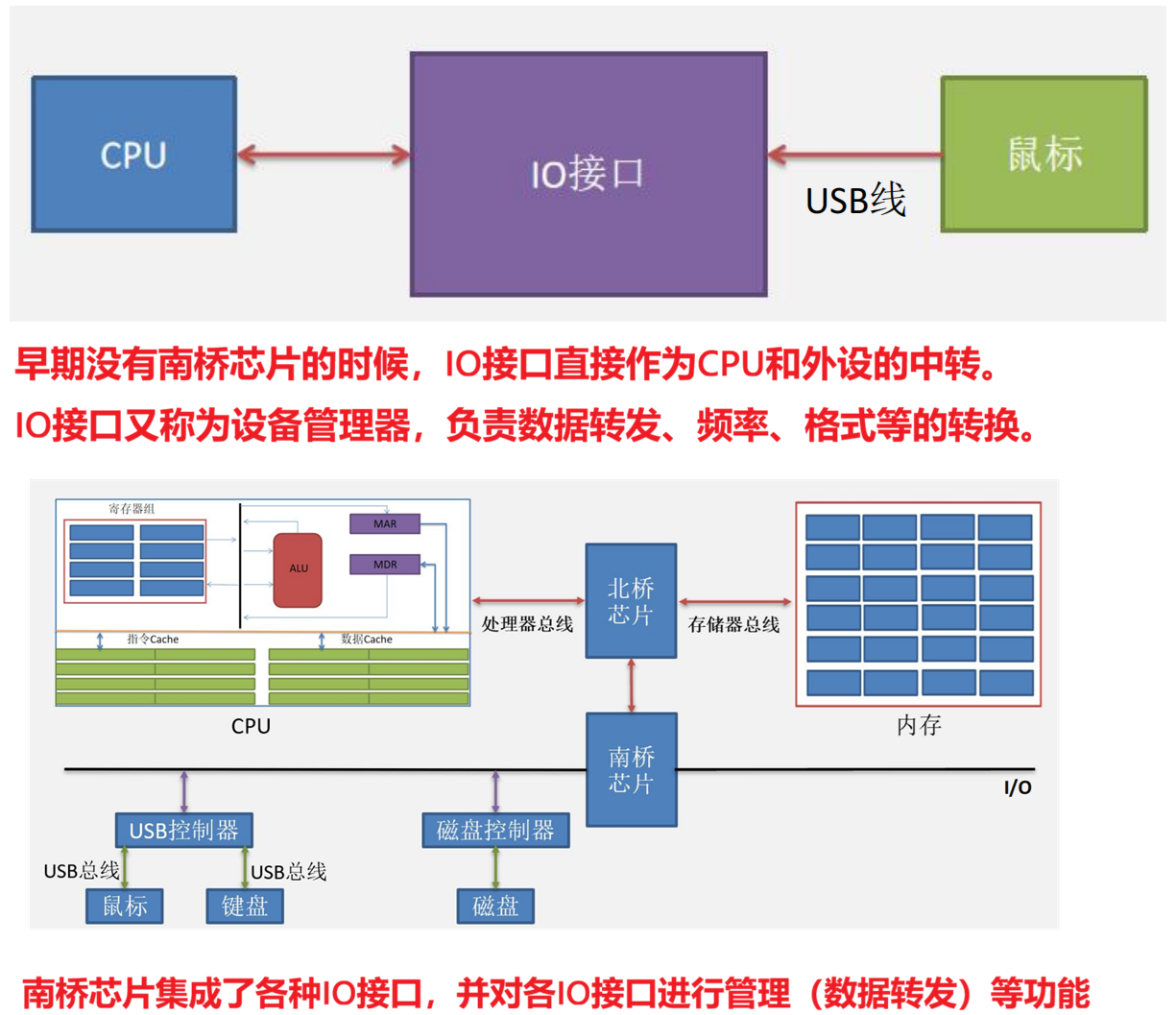
2.2 I/O地址编址方式
CPU要访问I/O接口中的寄存器,首先需要解决寻址问题。现代计算机主要采用两种编址方式:
2.2.1 I/O独立映射方式
在这种方式下,I/O设备拥有独立的地址空间,与内存地址空间完全分离。特点包括:
- 需要专门的I/O指令(如x86的IN/OUT)
- 地址解码简单,不会与内存冲突
- 早期计算机常用,现代系统中较少见
assembly复制; x86独立I/O示例
MOV DX, 3F8h ; 串口数据寄存器端口号
IN AL, DX ; 从端口读取数据
OUT DX, AL ; 向端口写入数据
2.2.2 内存映射I/O方式
现代计算机普遍采用的方式,将I/O寄存器映射到内存地址空间中:
- 使用普通内存访问指令操作I/O设备
- 硬件设计更简单统一
- 可能造成部分内存地址"浪费"
c复制// 内存映射I/O示例
#define UART_BASE 0xFE201000 // Raspberry Pi UART基地址
volatile uint32_t* uart_reg = (uint32_t*)UART_BASE;
// 读取UART状态
uint32_t status = *(uart_reg + 1);
// 写入UART数据
*(uart_reg) = 'A';
两种编址方式的对比:
| 特性 | I/O独立映射 | 内存映射I/O |
|---|---|---|
| 指令系统 | 专用I/O指令 | 普通内存指令 |
| 地址空间 | 独立I/O空间 | 共享内存空间 |
| 硬件复杂度 | 较高 | 较低 |
| 编程便利性 | 较差 | 较好 |
| 现代系统使用 | 较少 | 主流 |
3. CPU与外设的交互方式
3.1 程序查询(轮询)方式
这是最简单的I/O控制方式,CPU主动定期检查外设状态:
c复制// 轮询方式示例代码
while(1) {
// 读取状态寄存器
status = *status_reg;
// 检查就绪位
if(status & READY_BIT) {
// 读取数据
data = *data_reg;
process_data(data);
}
// 其他工作...
}
轮询方式的优缺点分析:
优点:
- 实现简单,无需额外硬件支持
- 适合简单嵌入式系统或状态变化缓慢的设备
缺点:
- CPU利用率极低,大部分时间在空转
- 实时性差,无法及时响应紧急事件
- 不适合多任务环境
在实际应用中,轮询方式常见于以下场景:
- 嵌入式系统中的简单传感器读取
- 调试阶段的临时实现
- 对实时性要求不高的简单设备
3.2 中断驱动方式
中断机制允许外设在需要CPU介入时主动发出信号:
c复制// 中断服务例程示例
void uart_isr() {
// 读取中断状态
status = *uart_status_reg;
if(status & RX_INTERRUPT) {
// 处理接收数据
data = *uart_data_reg;
buffer_push(rx_buf, data);
}
if(status & TX_INTERRUPT) {
// 处理发送完成
tx_complete = true;
}
}
中断处理流程详解:
- 中断请求(IRQ):外设通过中断控制器向CPU发送请求
- 中断响应:CPU完成当前指令后响应中断
- 现场保存:将PC、PSW等关键寄存器压栈
- 中断服务:执行对应的中断处理程序
- 现场恢复:恢复之前保存的寄存器状态
- 中断返回:继续执行被中断的程序
中断优先级的实现:
现代系统通常支持多级中断优先级,通过以下方式管理:
- 硬件优先级:中断控制器的固定优先级
- 软件优先级:通过中断屏蔽寄存器动态调整
- 嵌套中断:高优先级中断可打断低优先级处理
中断方式的优缺点:
优点:
- CPU利用率高,无需主动查询
- 实时性好,可快速响应外设请求
- 适合中低速设备(键盘、鼠标等)
缺点:
- 中断处理需要额外开销(保存/恢复现场)
- 高频中断可能导致系统性能下降
- 编程复杂度较高,需考虑竞态条件
在实际编程中,Linux内核的中断处理分为上半部(top half)和下半部(bottom half)。上半部处理紧急操作(如清除中断标志),下半部通过tasklet或工作队列处理耗时操作,这种设计平衡了响应速度和系统负载。
4. DMA技术深度解析
4.1 DMA的基本原理
DMA(Direct Memory Access)技术允许外设直接与内存交换数据,无需CPU参与数据传输过程。典型的DMA系统包含以下组件:
- DMA控制器:管理数据传输的专用硬件
- 源地址寄存器:数据传输的起始地址
- 目的地址寄存器:数据传输的目标地址
- 计数器:记录传输数据量
- 控制寄存器:配置传输参数(方向、模式等)
DMA传输的基本流程:
- CPU初始化DMA控制器(设置地址、计数器等)
- DMA控制器接管总线控制权
- DMA控制器完成数据传输
- DMA控制器释放总线,通知CPU传输完成
4.2 DMA的工作模式
4.2.1 块传输模式
在这种模式下,DMA控制器获得总线后,会连续传输整个数据块:
c复制// DMA块传输初始化示例
void setup_dma_block_transfer(void* src, void* dest, size_t size) {
// 设置源地址
dma_regs->src_addr = (uint32_t)src;
// 设置目标地址
dma_regs->dest_addr = (uint32_t)dest;
// 设置传输大小
dma_regs->count = size;
// 配置控制寄存器
dma_regs->ctrl = DMA_CTRL_ENABLE | DMA_CTRL_BLOCK_MODE;
// 启动传输
dma_regs->ctrl |= DMA_CTRL_START;
}
特点:
- 传输效率最高
- 总线占用时间长
- 可能导致CPU长时间停顿
4.2.2 周期窃取模式
DMA控制器只在CPU不使用总线时进行传输:
c复制// DMA周期窃取初始化示例
void setup_dma_cycle_steal(void* src, void* dest, size_t size) {
// 设置源地址
dma_regs->src_addr = (uint32_t)src;
// 设置目标地址
dma_regs->dest_addr = (uint32_t)dest;
// 设置传输大小
dma_regs->count = size;
// 配置控制寄存器
dma_regs->ctrl = DMA_CTRL_ENABLE | DMA_CTRL_CYCLE_STEAL;
// 启动传输
dma_regs->ctrl |= DMA_CTRL_START;
}
特点:
- CPU停顿时间短
- 总线利用率高
- 传输效率略低于块模式
4.2.3 透明模式
DMA只在CPU执行不需要访问总线的操作时传输数据:
特点:
- CPU完全无感知
- 传输效率最低
- 不影响CPU性能
4.3 DMA在现代系统中的应用
典型DMA应用场景:
- 存储设备:硬盘、SSD的数据传输
- 网络设备:网卡数据包收发
- 多媒体处理:音频/视频数据搬运
- 图形处理:显存与内存间的数据传输
Linux中的DMA API示例:
c复制// 分配DMA缓冲区
dma_addr_t dma_handle;
void* buffer = dma_alloc_coherent(dev, size, &dma_handle, GFP_KERNEL);
// 启动DMA传输
struct dma_async_tx_descriptor *tx;
tx = dmaengine_prep_slave_single(chan, dma_handle, size, direction, flags);
// 设置完成回调
tx->callback = dma_complete_callback;
tx->callback_param = callback_param;
// 提交传输
dmaengine_submit(tx);
dma_async_issue_pending(chan);
DMA性能优化技巧:
- 缓冲区对齐:确保DMA缓冲区按cache line对齐
- 批量传输:尽量使用大块传输而非多次小传输
- 流式DMA:对顺序访问使用流式预取
- 分散/聚集:利用SG-DMA处理不连续内存
5. 实际案例分析:磁盘I/O的全过程
让我们通过一个具体的例子——程序从磁盘读取文件,来看这些技术如何协同工作:
- 应用程序调用read()系统调用请求读取文件
- 文件系统检查页缓存,若未命中则发起磁盘I/O
- 块设备层将文件偏移转换为磁盘块地址
- SCSI/SATA驱动准备DMA传输描述符
- DMA控制器将磁盘数据直接传输到内存缓冲区
- 磁盘控制器在传输完成后发出中断
- 中断处理程序通知上层I/O完成
- 文件系统将数据拷贝到用户缓冲区
- 应用程序继续执行
在这个流程中,DMA负责实际的数据传输,中断用于通知完成,而CPU只在必要时介入,实现了高效的系统运作。