
1. 项目背景与核心价值
在嵌入式开发领域,传统开发模式通常需要开发者掌握C/C++等底层语言,这对于很多应用层开发者来说存在一定门槛。而将Python移植到MCU平台,则能够显著降低嵌入式开发的门槛。APM32F427作为一款基于Arm Cortex-M4内核的国产MCU,其运行频率高达200MHz,Flash容量达到1MB,RAM容量达到256KB,这为运行MicroPython提供了硬件基础。
这个项目的核心价值在于:
- 为嵌入式开发者提供更友好的开发体验
- 扩展Python在物联网领域的应用场景
- 验证国产MCU对高级语言的支持能力
- 为快速原型开发提供新思路
2. 硬件准备与环境搭建
2.1 硬件选型解析
APM32F427VGT6是极海半导体推出的一款高性能MCU,其主要参数如下:
| 参数 | 规格 |
|---|---|
| 内核 | Cortex-M4 |
| 主频 | 200MHz |
| Flash | 1MB |
| RAM | 256KB |
| GPIO | 多达114个 |
| 外设接口 | USB, CAN, SPI等 |
选择这款芯片的原因在于:
- 充足的RAM空间能够满足MicroPython运行时的内存需求
- 高性能CPU可以较好地处理Python解释器的开销
- 丰富的外设接口便于后续功能扩展
2.2 开发环境搭建步骤
-
工具链安装:
- 安装ARM GCC工具链(版本建议9-2020-q2-update)
- 安装OpenOCD用于调试(版本建议0.11.0)
- 安装Python3环境(用于构建MicroPython)
-
源码获取:
bash复制git clone --recursive https://github.com/micropython/micropython.git cd micropython git submodule update --init -
交叉编译工具配置:
在Makefile中设置正确的交叉编译工具路径:makefile复制
CROSS_COMPILE = arm-none-eabi- -
板级支持包准备:
需要为APM32F427准备特定的板级支持包,包括:- 时钟配置(确保200MHz主频正确设置)
- GPIO驱动实现
- 串口调试接口配置
3. MicroPython移植关键步骤
3.1 移植框架解析
MicroPython的移植主要涉及三个层次:
-
硬件抽象层(HAL):
- 实现基本的时钟、GPIO、定时器等驱动
- 确保中断处理机制正确
-
运行时环境:
- 内存管理适配(堆分配策略)
- 垃圾回收机制配置
-
外设支持:
- 基础GPIO控制
- 串口调试接口
- 其他扩展外设(如SPI、I2C等)
3.2 具体移植步骤
-
创建新板级目录:
bash复制cd ports/stm32/boards mkdir APM32F427 -
编写板级配置文件:
创建mpconfigboard.h文件,配置基础参数:c复制#define MICROPY_HW_BOARD_NAME "APM32F427" #define MICROPY_HW_MCU_NAME "APM32F427VGT6" #define MICROPY_HW_FLASH_FS_LABEL "apm32flash" // 时钟配置 #define MICROPY_HW_CLK_PLLM (25) #define MICROPY_HW_CLK_PLLN (400) #define MICROPY_HW_CLK_PLLP (RCC_PLLP_DIV2) #define MICROPY_HW_CLK_PLLQ (8) -
实现GPIO驱动:
在modmachine.c中实现GPIO控制函数:c复制STATIC mp_obj_t machine_pin_obj_init_helper(const machine_pin_obj_t *self, size_t n_args, const mp_obj_t *pos_args, mp_map_t *kw_args) { // GPIO初始化实现 } -
内存管理配置:
调整mpconfigboard.mk中的内存分配:makefile复制
LD_FILES = boards/APM32F427/APM32F427.ld MICROPY_PY_THREAD = 0
4. 点灯实验实现细节
4.1 Python脚本编写
在MicroPython环境下,控制LED的Python脚本非常简单:
python复制import machine
import time
# 初始化GPIO
led = machine.Pin('PC13', machine.Pin.OUT)
while True:
led.value(1) # 点亮LED
time.sleep(1)
led.value(0) # 熄灭LED
time.sleep(1)
4.2 固件烧录流程
-
编译固件:
bash复制
make BOARD=APM32F427 -
生成DFU文件:
bash复制
python3 tools/dfu.py --build build-APM32F427/firmware.bin -
进入DFU模式:
- 将BOOT0引脚拉高
- 复位开发板
-
使用dfu-util烧录:
bash复制
dfu-util -a 0 -D build-APM32F427/firmware# 1. 概述
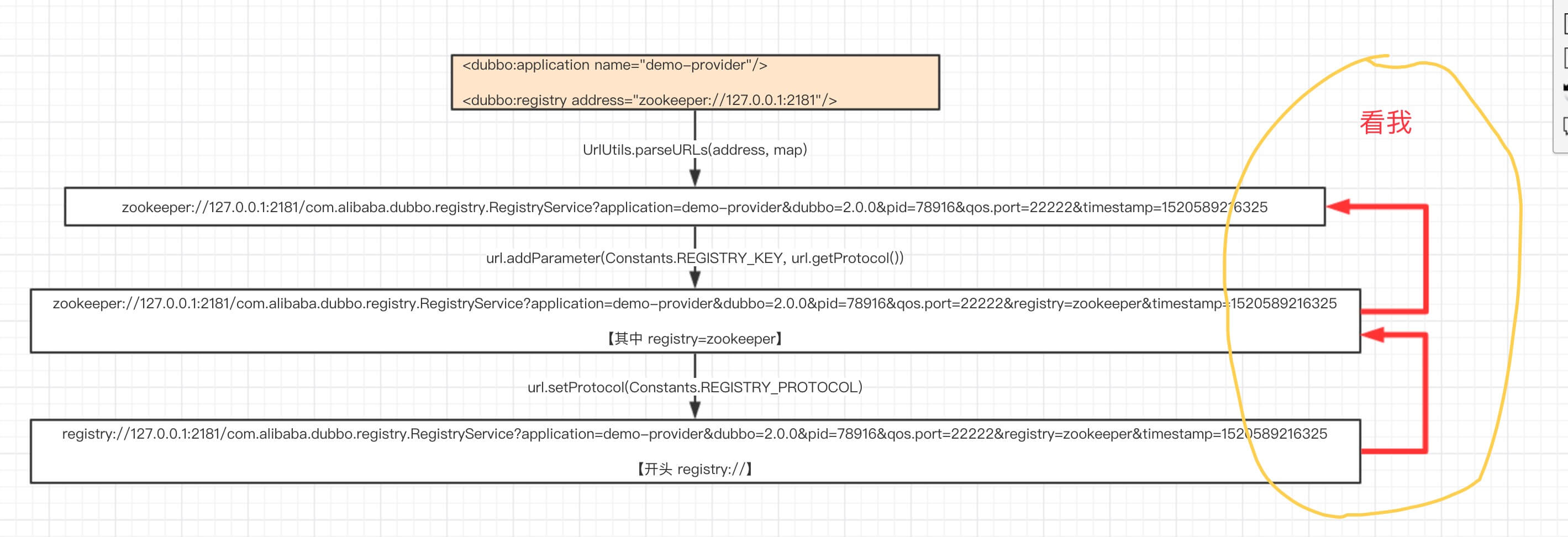
本文分享 Dubbo 的线程池策略。在 《精尽 Dubbo 源码分析 —— 线程池》 一文中,我们已经看到了多种线程池和线程队列,Dubbo 是如何选择哪一个使用的呢?
2. 线程池策略
Dubbo 的线程池策略,使用 dubbo.protocol.threadpool 配置项,设置。目前支持四种策略:
fixed固定大小线程池,启动时建立线程,不关闭,一直持有。(缺省)cached缓存线程池,空闲一分钟自动删除,需要时重建。limited可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。eager优先创建Worker线程池。在任务数量大于corePoolSize但是小于maximumPoolSize时,优先创建Worker来处理任务。当任务数量大于maximumPoolSize时,将任务放入阻塞队列中。阻塞队列充满时抛出RejectedExecutionException。(相比于cached:cached在任务数量超过maximumPoolSize时直接抛出异常而不是将任务放入阻塞队列)
3. 源码实现
在 DubboProtocol#createServer(...) 方法中,我们看到如下代码:
java复制// DubboProtocol.java
private ExchangeServer createServer(URL url) {
// ... 省略无关代码
// 添加线程池
url = url.addParameterIfAbsent(Constants.THREADPOOL_KEY, Constants.DEFAULT_THREA[DPO](https://taotoken.net?utm_source=hardware)OL); // fixed 为默认
// ... 省略无关代码
ExchangeServer server;
try {
// 创建 ExchangeServer 对象
server = Exchangers.bind(url, requestHandler);
} catch (RemotingException e) {
throw new RpcException("Fail to start server(url: " + url + ") " + e.getMessage(), e);
}
// ... 省略无关代码
return server;
}
-
在该方法中,我们可以看到,
THREADPOOL_KEY的默认配置是DEFAULT_THREADPOOL,即"fixed"。 -
在
Exchangers#bind(URL url, ExchangeHandler handler)方法中,我们看到如下代码:java复制// Exchangers.java public static ExchangeServer bind(URL url, ExchangeHandler handler) throws RemotingException { if (url == null) { throw new IllegalArgumentException("url == null"); } if (handler == null) { throw new IllegalArgumentException("handler == null"); } // 添加编解码器 url = url.addParameterIfAbsent(Constants.CODEC_KEY, "exchange"); // 创建 HeaderExchangeServer 对象 return getExchanger(url).bind(url, handler); }-
在该方法中,调用
#getExchanger(url)方法,获得Exchanger对象,默认是HeaderExchanger对象。代码如下:java复制public static Exchanger getExchanger(URL url) { String type = url.getParameter(Constants.EXCHANGER_KEY, Constants.DEFAULT_EXCHANGER); return getExchanger(type); } public static Exchanger getExchanger(String type) { return ExtensionLoader.getExtensionLoader(Exchanger.class).getExtension(type); }DEFAULT_EXCHANGER为"header",即HeaderExchanger。
-
然后,调用
HeaderExchanger#bind(URL url, ExchangeHandler handler)方法,创建HeaderExchangeServer对象。代码如下:java复制// HeaderExchanger.java @Override public ExchangeServer bind(URL url, ExchangeHandler handler) throws RemotingException { // 创建 HeaderExchangeServer 对象 return new HeaderExchangeServer(Transporters.bind(url, new DecodeHandler(new HeaderExchangeHandler(handler)))); }-
在该方法中,我们看到
Transporters#bind(URL url, ChannelHandler... handlers)方法,创建TransportServer对象。代码如下:java复制// Transporters.java public static Server bind(URL url, ChannelHandler... handlers) throws RemotingException { if (url == null) { throw new IllegalArgumentException("url == null"); } if (handlers == null || handlers.length == 0) { throw new IllegalArgumentException("handlers == null"); } ChannelHandler handler; if (handlers.length == 1) { handler = handlers[0]; } else { // 如果 handlers 数量大于 1,则创建 ChannelHandler 分发器 handler = new ChannelHandlerDispatcher(handlers); } // 创建 TransportServer 对象 return getTransporter().bind(url, handler); } public static Transporter getTransporter() { return ExtensionLoader.getExtensionLoader(Transporter.class).getAdaptiveExtension(); }-
在该方法中,调用
#getTransporter()方法,获得Transporter自适应拓展对象,默认是NettyTransporter对象。 -
然后,调用
NettyTransporter#bind(URL url, ChannelHandler handler)方法,创建NettyServer对象。代码如下:java复制// NettyTransporter.java @Override public Server bind(URL url, ChannelHandler handler) throws RemotingException { // 创建 NettyServer 对象 return new NettyServer(url, handler); }-
在该方法中,创建
NettyServer对象。在构造方法中,会调用AbstractServer#AbstractServer(URL url, ChannelHandler handler)父类构造方法。代码如下:java复制// AbstractServer.java public AbstractServer(URL url, ChannelHandler handler) throws RemotingException { // 父类构造方法 super(url, handler); // 本地地址 localAddress = getUrl().toInetSocketAddress(); // 获得服务器 IP String bindIp = getUrl().getParameter(Constants.BIND_IP_KEY, getUrl().getHost()); // 获得服务器端口 int bindPort = getUrl().getParameter(Constants.BIND_PORT_KEY, getUrl().getPort()); if (url.getParameter(Constants.ANYHOST_KEY, false) || NetUtils.isInvalidLocalHost(bindIp)) { bindIp = NetUtils.ANYHOST; } // 绑定地址 bindAddress = new InetSocketAddress(bindIp, bindPort); // 最大可连接数 this.accepts = url.getParameter(Constants.ACCEPTS_KEY, Constants.DEFAULT_ACCEPTS); // 空闲超时时间,默认 60 * 1000 毫秒 this.idleTimeout = url.getParameter(Constants.IDLE_TIMEOUT_KEY, Constants.DEFAULT_IDLE_TIMEOUT); try { // 启动服务器 doOpen(); if (logger.isInfoEnabled()) { logger.info("Start " + getClass().getSimpleName() + " bind " + getBindAddress() + ", export " + getLocalAddress()); } } catch (Throwable t) { throw new RemotingException(url.toInetSocketAddress(), null, "Failed to bind " + getClass().getSimpleName() + " on " + getLocalAddress() + ", cause: " + t.getMessage(), t); } // 创建线程池 executor = executorRepository.createExecutorIfAbsent(url); }-
在该方法中,会调用
ExecutorRepository#createExecutorIfAbsent(URL url)方法,创建线程池。代码如下:java复制// ExecutorRepository.java /** * 数据交换层服务器线程池 * key: 服务地址 * value: 线程池 */ private final ConcurrentMap<String, ExecutorService> dataExchangeServerExecutor = new ConcurrentHashMap<>(); public ExecutorService createExecutorIfAbsent(URL url) { // 获得线程数,即服务提供者线程池的固定大小,默认为 200 Integer coreSize = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS); // 获得队列大小,默认为 0 Integer queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES); // 获得线程池名称 String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME); // 创建或获得线程池服务对象 ExecutorService executor = dataExchangeServerExecutor.computeIfAbsent(addr, k -> createExecutor(url, name, coreSize, queues)); return executor; } private ExecutorService createExecutor(URL url, String name, int coreSize, int queues) { // 创建线程池 return createExecutor(url, (ThreadPool) ExtensionLoader.getExtensionLoader(ThreadPool.class).getAdaptiveExtension(), name, coreSize, queues); } public ExecutorService createExecutor(URL url, ThreadPool threadPool, String name, int coreSize, int queues) { // 创建线程池 return threadPool.getExecutor(url, name, coreSize, queues); }-
在该方法中,会调用
ThreadPool#getExecutor(URL url, String name, int coreSize, int queues)方法,创建线程池。而ThreadPool的默认实现是FixedThreadPool,即fixed策略。代码如下:java复制// FixedThreadPool.java @Override public ExecutorService getExecutor(URL url, String name, int cores, int queues) { // 创建线程池 return new ThreadPoolExecutor(cores, cores, 0, TimeUnit.MILLISECONDS, queues == 0 ? new SynchronousQueue<Runnable>() : (queues < 0 ? new LinkedBlockingQueue<Runnable>() : new LinkedBlockingQueue<Runnable>(queues)), new NamedInternalThreadFactory(name, true), new AbortPolicyWithReport(name, url)); }- 根据不同的队列数,使用不同的队列实现:
queues == 0, SynchronousQueue 对象。queues < 0, LinkedBlockingQueue 对象。queues > 0,带队列数的 LinkedBlockingQueue 对象。
- 线程工厂,NamedInternalThreadFactory 对象。
- 拒绝策略,AbortPolicyWithReport 对象。详细解析,见 《精尽 Dubbo 源码分析 —— 线程池》 的 「4. AbortPolicyWithReport」 部分。
- 根据不同的队列数,使用不同的队列实现:
-
-
-
-
-
-
4. 不同策略
在 dubbo-common 模块的 org.apache.dubbo.common.threadpool.support 包下:
4.1 FixedThreadPool
com.alibaba.dubbo.common.threadpool.support.fixed.FixedThreadPool ,实现 ThreadPool 接口,固定大小线程池,启动时建立线程,不关闭,一直持有。代码如下:
java复制public class FixedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
// 线程名
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
// 线程数
int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS);
// 队列数
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
// 创建执行器
return new ThreadPoolExecutor(threads, threads, 0, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
- 默认情况下,采用 SynchronousQueue 队列。关于 SynchronousQueue 队列,笔者推荐阅读 《Java SynchronousQueue Examples (in thread pool)》 文章。
- 核心线程数 = 最大线程数。
4.2 CachedThreadPool
com.alibaba.dubbo.common.threadpool.support.cached.CachedThreadPool ,实现 ThreadPool 接口,缓存线程池,空闲一定时长,自动删除,需要时重建。代码如下:
java复制public class CachedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
// 线程池名
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
// 核心线程数
int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS);
// 最大线程数
int threads = url.getParameter(Constants.THREADS_KEY, Integer.MAX_VALUE);
// 队列数
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
// 线程空闲时长
int alive = url.getParameter(Constants.ALIVE_KEY, Constants.DEFAULT_ALIVE);
// 创建执行器
return new ThreadPoolExecutor(cores, threads, alive, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
- 默认情况下,
cores = 0threads = Integer.MAX_VALUEqueues = 0alive = 60 * 1000毫秒。 - 和
FixedThreadPool不同的是:- 队列使用 SynchronousQueue 队列。
- 线程空闲时长是
alive参数,默认为 60 秒。意味着,空闲超过 60 秒的线程,会被回收。 - 最大线程数为
threads参数,默认为Integer.MAX_VALUE。
4.3 LimitedThreadPool
com.alibaba.dubbo.common.threadpool.support.limited.LimitedThreadPool ,实现 ThreadPool 接口,可伸缩线程池,但池中的线程数只会增长不会收缩。只增长不收缩的目的是为了避免收缩时突然来了大流量引起的性能问题。代码如下:
java复制public class LimitedThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
// 线程名
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
// 核心线程数
int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS);
// 最大线程数
int threads = url.getParameter(Constants.THREADS_KEY, Constants.DEFAULT_THREADS);
// 队列数
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
// 创建执行器
return new ThreadPoolExecutor(cores, threads, Long.MAX_VALUE, TimeUnit.MILLISECONDS,
queues == 0 ? new SynchronousQueue<Runnable>() :
(queues < 0 ? new LinkedBlockingQueue<Runnable>()
: new LinkedBlockingQueue<Runnable>(queues)),
new NamedThreadFactory(name, true), new AbortPolicyWithReport(name, url));
}
}
- 和
FixedThreadPool不同的是:- 队列使用 SynchronousQueue 队列。
- 线程空闲时长是
Long.MAX_VALUE毫秒。意味着,空闲线程不会被回收。 - 最大线程数为
threads参数,默认为 200 。
4.4 EagerThreadPool
com.alibaba.dubbo.common.threadpool.support.eager.EagerThreadPool ,实现 ThreadPool 接口,在任务数量大于 corePoolSize 但是小于 maximumPoolSize 时,优先创建线程来处理任务。当任务数量大于 maximumPoolSize 时,将任务放入阻塞队列中。阻塞队列充满时抛出 RejectedExecutionException 异常。代码如下:
java复制public class EagerThreadPool implements ThreadPool {
@Override
public Executor getExecutor(URL url) {
// 线程名
String name = url.getParameter(Constants.THREAD_NAME_KEY, Constants.DEFAULT_THREAD_NAME);
// 核心线程数
int cores = url.getParameter(Constants.CORE_THREADS_KEY, Constants.DEFAULT_CORE_THREADS);
// 最大线程数
int threads = url.getParameter(Constants.THREADS_KEY, Integer.MAX_VALUE);
// 队列数
int queues = url.getParameter(Constants.QUEUES_KEY, Constants.DEFAULT_QUEUES);
// 线程空闲时长
int alive = url.getParameter(Constants.ALIVE_KEY, Constants.DEFAULT_ALIVE);
// 创建执行器
// init queue and executor
TaskQueue<Runnable> taskQueue = new TaskQueue<Runnable>(queues <= 0 ? 1 : queues);
EagerThreadPoolExecutor executor = new EagerThreadPoolExecutor(cores,
threads,
alive,
TimeUnit.MILLISECONDS,
taskQueue,
new NamedThreadFactory(name, true),
new AbortPolicyWithReport(name, url));
taskQueue.setExecutor(executor);
return executor;
}
}
- 默认情况下,
cores = 0threads = Integer.MAX_VALUEqueues = 0alive = 60 * 1000毫秒。 - 和
CachedThreadPool不同的是:- 队列使用 TaskQueue 队列。并且,该队列带有
executor属性,即线程池。 - 线程池使用 EagerThreadPoolExecutor 执行器。
- 队列使用 TaskQueue 队列。并且,该队列带有
4.4.1 TaskQueue
org.apache.dubbo.common.threadpool.support.eager.TaskQueue ,继承 LinkedBlockingQueue 类,任务队列。代码如下:
java复制public class TaskQueue<R extends Runnable> extends LinkedBlockingQueue<Runnable> {
private static final long serialVersionUID = -2635853580887179627L;
/**
* 线程池
*/
private EagerThreadPoolExecutor executor;
public TaskQueue(int capacity) {
super(capacity);
}
public void setExecutor(EagerThreadPoolExecutor exec) {
executor = exec;
}
@Override
public boolean offer(Runnable runnable) {
if (executor == null) {
throw new RejectedExecutionException("The task queue does not have executor!");
}
// 当前线程数
int currentPoolThreadSize = executor.getPoolSize();
// 有空闲线程,添加到队列中
if (executor.getSubmittedTaskCount() < currentPoolThreadSize) {
return super.offer(runnable);
}
// 当前线程数小于最大线程数,返回 false ,让线程池创建新的线程
if (currentPoolThreadSize < executor.getMaximumPoolSize()) {
return false;
}
// 添加到队列中
return super.offer(runnable);
}
/**
* 重试执行任务
*
* 1. 返回当前队列
* 2. 返回父类队列
*
* @return 队列
*/
public RetryOfferTask<Runnable> retryOffer(Runnable o, long timeout, TimeUnit unit) throws InterruptedException {
if (executor.isShutdown()) {
throw new RejectedExecutionException("Executor is shutdown!");
}
return new RetryOfferTask<Runnable>(o, this, unit.toMillis(timeout));
}
}
executor属性,线程池。通过#setExecutor(EagerThreadPoolExecutor executor)方法设置。#offer(Runnable runnable)方法,代码如下:- 当前线程数大于提交的任务数时,调用父类方法,添加到队列中。
- 当前线程数小于最大线程数时,返回
false,让线程池创建新的线程。 - 即,在任务数量大于
corePoolSize但是小于maximumPoolSize时,优先创建线程来处理任务。
#retryOffer(Runnable o, long timeout, TimeUnit unit)方法,重试执行任务。目前该方法未被使用。
4.4.2 EagerThreadPoolExecutor
org.apache.dubbo.common.threadpool.support.eager.EagerThreadPoolExecutor ,继承 ThreadPoolExecutor 类,优先创建线程来处理任务。代码如下:
java复制public class EagerThreadPoolExecutor extends ThreadPoolExecutor {
/**
* 提交的任务数量
*/
private final AtomicInteger submittedTaskCount = new AtomicInteger(0);
public EagerThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit, TaskQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue, threadFactory, handler);
}
public int getSubmittedTaskCount() {
return submittedTaskCount.get();
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
submittedTaskCount.decrementAndGet();
}
@Override
public void execute(Runnable command) {
if (command == null) {
throw new NullPointerException();
}
// 提交的任务数量 +1
submittedTaskCount.incrementAndGet();
try {
// 执行任务
super.execute(command);
} catch (RejectedExecutionException rx) {
// 被拒绝,尝试添加到队列中
final TaskQueue queue = (TaskQueue) super.getQueue();
try {
if (!queue.retryOffer(command, 0, TimeUnit.MILLISECONDS)) {
submittedTaskCount.decrementAndGet();
throw new RejectedExecutionException("Queue capacity is full.", rx);
}
} catch (InterruptedException x) {
submittedTaskCount.decrementAndGet();
throw new RejectedExecutionException(x);
}
} catch (Throwable t) {
// 提交的任务数量 -1
submittedTaskCount.decrementAndGet();
throw t;
}
}
}
submittedTaskCount属性,提交的任务数量。#execute(Runnable command)方法,提交任务给线程池执行。- 提交的任务数量 +1 。
- 调用父类方法,执行任务。
- 若被拒绝,调用
TaskQueue#retryOffer(command, 0, TimeUnit.MILLISECONDS)方法,重试添加到队列中。 - 若发生异常,提交的任务数量 -1 。
#afterExecute(Runnable r, Throwable t)方法,执行任务完成时,提交的任务数量 -1 。
5. 如何选择线程池策略
笔者整理了一张三种线程池策略的对比图:
| 策略 | 核心线程数 | 最大线程数 | 队列 | 队列长度 | 线程空闲时间 | 拒绝策略 |
|---|---|---|---|---|---|---|
| fixed | dubbo.protocol.threads 默认 200 |
同核心线程数 | SynchronousQueue |
0 | 0 | AbortPolicyWithReport |
| cached | dubbo.protocol.corethreads 默认 0 |
dubbo.protocol.threads 默认 Integer.MAX_VALUE |
SynchronousQueue |
1 | dubbo.protocol.alive 默认 60 * 1000 |
AbortPolicyWithReport |
| limited | dubbo.protocol.corethreads 默认 0 |
dubbo.protocol.threads 默认 200 |
SynchronousQueue |
0 | Long.MAX_VALUE | AbortPolicyWithReport |
| eager | dubbo.protocol.corethreads 默认 0 |
dubbo.protocol.threads 默认 Integer.MAX_VALUE |
TaskQueue |
dubbo.protocol.queues 默认 0 |
dubbo.protocol.alive 默认 60 * 1000 |
AbortPolicyWithReport |
- 在绝大多数情况下,使用
fixed策略。具体的原因,胖友可以搜索下,为什么SynchronousQueue的性能好。 - 在极端情况下,使用
eager策略。例如说,耗时高,且并发量波动大。